「すぐに役立つ統計のコツ」(オーム社)の「クラスター分析」(117ページ)を参考に、次の例題を"データ解析環境R"で気軽に楽しんで見ましょう。
ここでは、
入院患者(女性)のアンケートから抽出した"語句(Words)" の出現頻度から入院患者に共通する心理などを考えて見ましょう。
(Week-1:入院1週間、Week-2:入院2週間、Wek-3:入院3週間)
入院患者(女性)のアンケートから抽出した"語句(Words)" の出現頻度から入院患者に共通する心理などを考えて見ましょう。
(Week-1:入院1週間、Week-2:入院2週間、Wek-3:入院3週間)
表1 女性入院患者から抽出した語句(Words)
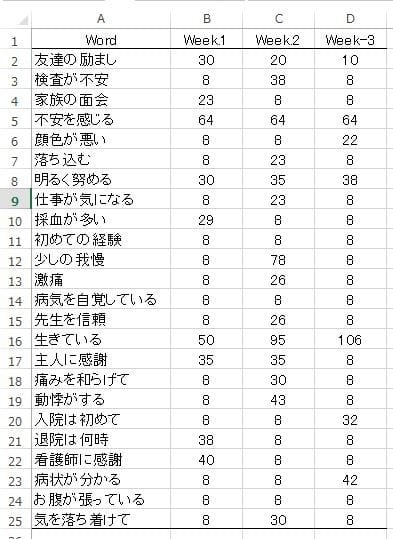
表1のWords について階層的クラスター分析を行い "Words" を整理し、その特徴を見てみましょう。
表1が Excel であるなら、
コピー&ペーストで「R」に読込んで下さい。
***
dat<- read.delim("clipboard", header=T, row.names=1) # row.names=1 はWords名を除く指示
head(dat)
dat<- read.delim("clipboard", header=T, row.names=1) # row.names=1 はWords名を除く指示
head(dat)
words<- dist(dat[, 1:3], "euclidean") # 頻度をユークリッド距離に変換
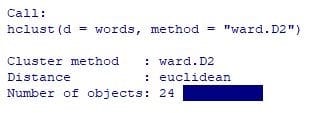
(words.hc<- hclust(words, method="ward.D2")) # ward.D2 を使用
(words.hc<- hclust(words, method="ward.D2")) # ward.D2 を使用
plot(words.hc)
#「R バージョン3.1.0」以降では"ward.D2"を指定して下さい。すなわち、hclust(dat, method=”ward.D2″) と指定、
# なお、「Rバージョン3.0.3」 までは、hclust(dat, method=”ward.D”) とします。
# なお、「Rバージョン3.0.3」 までは、hclust(dat, method=”ward.D”) とします。
出力結果:
ここでの、クラスターの方法は"ウォードD2法"、距離は"ユークリッド距離"ですが、その他にも色々なクラスターの方法や類似度=距離があります。
クラスター分析には、ある程度の試行錯誤が伴います。
***
クラスター分析には、ある程度の試行錯誤が伴います。
***
図1 デンドログラム(樹枝図)
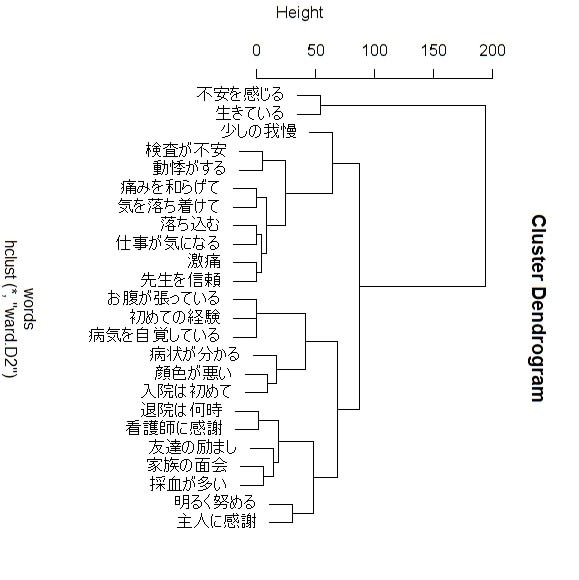
樹枝図の高さを揃えていません。揃えるなら、
***
plot(words.hc, hang=-1)
***
とします。
plot(words.hc, hang=-1)
***
とします。
この図1から、入院患者のアンケート回答に内在する心理状態を知ることが出来でしょうか・・?
大きく3つのクラスターに分かれた語句の出現頻度から、
例えば
例えば
①「不安を感じる、生きている」などは、"不安ながらも助かった" ことの実感が感じられます。
②「検査が不安、動悸がする、・・、気を落ち着けて、落ち込む」などは、検査結果の不安やネガティブな心理が、
そして「激痛、先生を信頼」は医師を信頼して痛みに耐えている心情かも知れません。
③「お腹が張っている、・・、病状が分かる、顔色が悪い」などは、まだ症状があり、病気を自覚している様です。そして、
④「退院は何時、看護師に感謝、友達の励まし」などは、回復と退院を待ちわびる心情が、そして、
「明るく務める、主人に感謝」は夫や家族に心配を掛けないように気配りしているのだろうか。
②「検査が不安、動悸がする、・・、気を落ち着けて、落ち込む」などは、検査結果の不安やネガティブな心理が、
そして「激痛、先生を信頼」は医師を信頼して痛みに耐えている心情かも知れません。
③「お腹が張っている、・・、病状が分かる、顔色が悪い」などは、まだ症状があり、病気を自覚している様です。そして、
④「退院は何時、看護師に感謝、友達の励まし」などは、回復と退院を待ちわびる心情が、そして、
「明るく務める、主人に感謝」は夫や家族に心配を掛けないように気配りしているのだろうか。
以上は、
筆者の勝手な解釈であり、アンケート(語句)の出現頻度に共通する女性の心理が表れている様にも思われます・・?
実際には、
研究者自身の知識・経験から読み解き、共通する因子名を命名しても良いでしょう。
筆者の勝手な解釈であり、アンケート(語句)の出現頻度に共通する女性の心理が表れている様にも思われます・・?
実際には、
研究者自身の知識・経験から読み解き、共通する因子名を命名しても良いでしょう。
ここでの最適なクラスター数はいくつでしょうか・・?
図1のデンドログラムからは"3~4"ってところでしょうか。
それでは、
非階層的クラスター分析としてよく知られている "K-means法" を簡単にご紹介しておきましょう。
非階層的クラスター分析としてよく知られている "K-means法" を簡単にご紹介しておきましょう。
***
# K-Means Clustering with 3 clusters
fit <- kmeans(dat,3 ) # クラスター数を3としてみる。
# K-Means Clustering with 3 clusters
fit <- kmeans(dat,3 ) # クラスター数を3としてみる。
library(cluster)
fit <- kmeans(dat,3 )
clusplot(dat, fit$cluster, color=TRUE , shade=FALSE, labels=2)
fit <- kmeans(dat,3 )
clusplot(dat, fit$cluster, color=TRUE , shade=FALSE, labels=2)
出力結果;
図2 K-means によるクラスタープロット
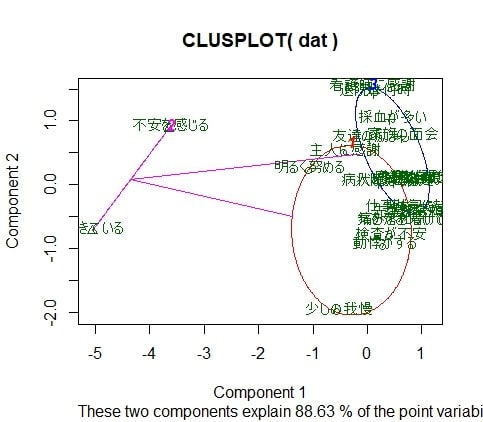
クラスター数は"3"程度が良さそうですが、色々な方法でやって見て下さい。
***
***
詳しく知りたいなら、下記URL(統計学入門:杉本典夫先生)をお勧めします。
http://www.snap-tck.com/room04/c01/stat/stat20/stat2001.html
http://www.snap-tck.com/room04/c01/stat/stat20/stat2001.html
初心者なら、当所の「やさしい医学統計手法」で大まかだけどお役に立てば嬉しいです。
http://kstat.sakura.ne.jp/medical/med_029.htm
http://kstat.sakura.ne.jp/medical/med_029.htm
情報統計研究所はここから!