JASPで一元配置分散分析をやってみましょう。
例題は、
「統計学入門、第4章 多標本のデータ処理」(杉本典夫 先生)から引用させて頂きます。
例題は、
「統計学入門、第4章 多標本のデータ処理」(杉本典夫 先生)から引用させて頂きます。
下記URLにアクセスし、
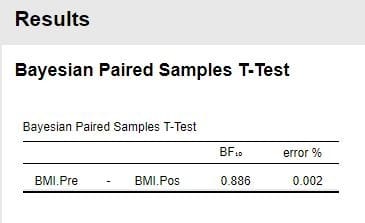
一元配置分散分析の「表4.1.1 薬剤投与後の収縮期血圧(mmHg)」のデータを Excel に図1のように入力し「.csv」形式で、例えば、「ANOVA1.csv」などとして保存して下さい。
一元配置分散分析の「表4.1.1 薬剤投与後の収縮期血圧(mmHg)」のデータを Excel に図1のように入力し「.csv」形式で、例えば、「ANOVA1.csv」などとして保存して下さい。
www.snap-tck.com/room04/c01/stat/stat04/stat0401.html
図1 データ入力形式
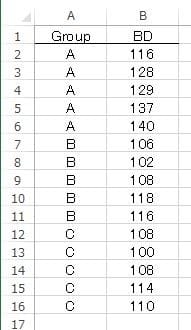
図1注釈:
Group=A剤投与群、B剤投与群、C剤投与群、BD=収縮期血圧
JASPの実行;
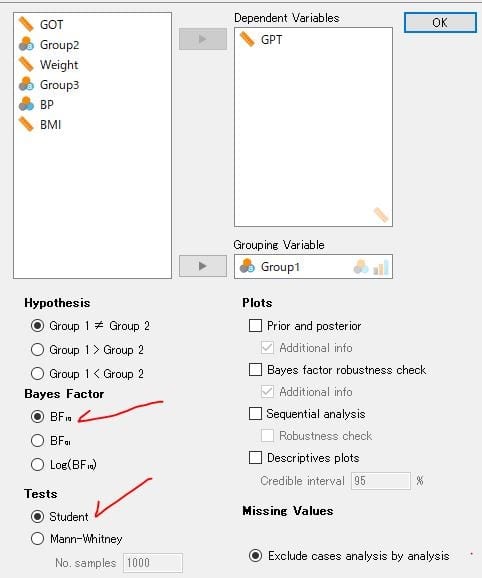
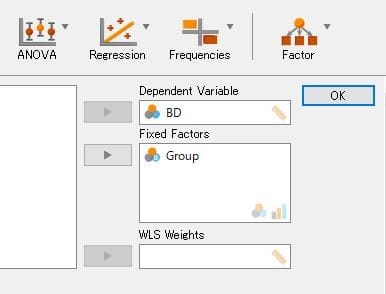
「ANOVA1.csv」の読込→ANOVAアイコン→変数の選択
↓
図1 変数の選択
↓
図1 変数の選択
↓
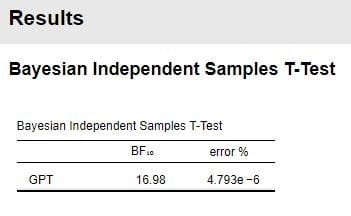
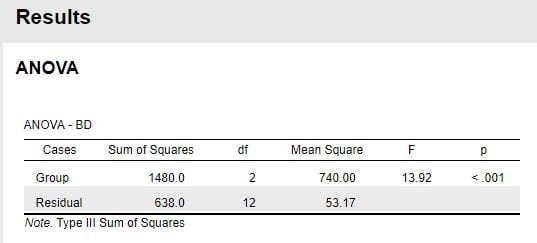
図2 一元配置ANOVAの結果
↓
図3 多重比較の選択
図3 多重比較の選択
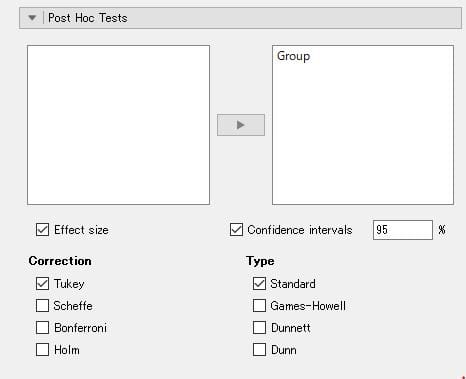
☑Effect size(効果量)、☑Confidence intervals[95]%(95%信頼区間)
Correation(多重比較)
☑Tukey、☑Standard
↓
図4 多重比較の結果
☑Tukey、☑Standard
↓
図4 多重比較の結果

↓
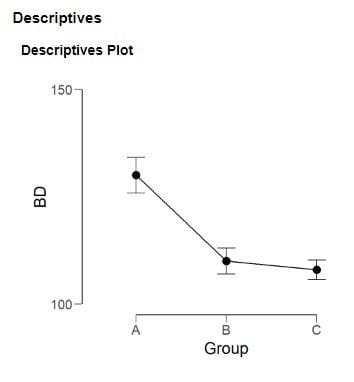
図5 分散分析の図示の方法(Descriptives Plots)
図5 分散分析の図示の方法(Descriptives Plots)
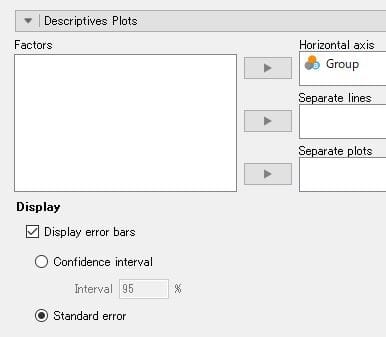
☑Display error bars(エラーバー)、☑Standard error(標準誤差)
↓
図6 「平均値±標準誤差」の図示
以上は、「データに対応がない場合」の一元配置分散分析でした。なお、結果の解釈などは「統計学入門、第4章 多標本のデータ処理」をご参考になさって下さい。
次回は、
「データに対応がある場合」の方法をご紹介するつもりです。
次回に続く!
情報統計研究所はここから。