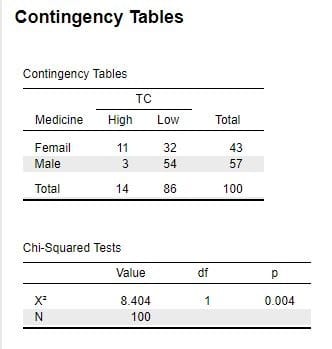
前回「新・医学と統計(18)」の分割表(Frequency.csv)を用いて「Baysian Contingency Tables」をやってみましょう。
JASP→Frequencies→Bayesian Contingency Tables
↓
新・医学と統計(18)の図1と同じ要領で変数を選択
↓
図1 検定方法の選択
↓
新・医学と統計(18)の図1と同じ要領で変数を選択
↓
図1 検定方法の選択

Statistics のデフォルトは、
◎ Indep.multinominal row fixed(行の固定)
◎ Indep.multinominal row fixed(行の固定)
となっています。
Additional Statistics☑ Log odds ratio (2×2 only)をチェックしてみましょう。
↓
図2 出力結果
↓
図2 出力結果

***
医学研究などにおいて分割表の形式は研究(実験)方法によって変わってくるものです。
医学研究などにおいて分割表の形式は研究(実験)方法によって変わってくるものです。
通常、次のような場合が考えられます。
・度数が固定されていない。
・総度数が決まっている。
・行の度数が決まっている。
・列の度数が決まっている。
・度数が固定されていない。
・総度数が決まっている。
・行の度数が決まっている。
・列の度数が決まっている。
これらは、医学実験などによって決まっていたりします。
例えば、
被験者数などが事前に決まっている場合などでは総数固定になります。
例えば、
被験者数などが事前に決まっている場合などでは総数固定になります。
分割表のベイズ分析のために開発された主に次の4つのプラン(スキーム)を検討することが出来ます。
Poisson(ポアソン)、 joint multinomial(結合又は同時多項)、independent multinomial(独立多項)、hypergeometric(超幾何)
Poisson(ポアソン)、 joint multinomial(結合又は同時多項)、independent multinomial(独立多項)、hypergeometric(超幾何)
Poisson(ポアソン):
各セル数はすべてランダムでポアソン分布に従うものです。
各セル数はすべてランダムでポアソン分布に従うものです。
joint multinomial(結合多項):
ポアソンと同じですが総数が固定されています。
ポアソンと同じですが総数が固定されています。
independent multinomial(独立多項):
これは行と列の合計が決まっているもので実験心理学でよく用いられています。
JASPでは default となっています。
これは行と列の合計が決まっているもので実験心理学でよく用いられています。
JASPでは default となっています。
hypergeometric(超幾何):
これは行と列の両方の合計が固定された Fisher's test の計算と考えて下さい。
これは行と列の両方の合計が固定された Fisher's test の計算と考えて下さい。
Fisher's test の計算は「すぐに役立つ統計のコツ」(オーム社刊)の 44ページに Excelでの計算法をご紹介しています。
文献:
Jamil, T., Ly, A/, & Wagenmakers, E-J.(2017). Default "Gunel and Dickey" Bayes factors for contingency tables.
Manuscript submitted for publication (Preprint).
Jamil, T., Ly, A/, & Wagenmakers, E-J.(2017). Default "Gunel and Dickey" Bayes factors for contingency tables.
Manuscript submitted for publication (Preprint).
次回に続く!
情報統計研究所をご気軽にご利用くださいませ。