








アドレスは以下の通り
https://www.youtube.com/watch?v=Gu31SuTwUZw
「スタビジbyウマたん」にケチ付ける訳じゃないが、正直R言語とPython(或いはJupyter)の簡便な機能にゾッとした。
まぁJupyterで機械学習の45分x15巻の動画をこなしたが「実感」もなくR言語はNHKのコロナ感染データが面白くて手を染めたが、インストールが糞で、Rstudio以外は、動いたり動かなかったりしている。
それでカリキュラムを勝手にこなしていると「回帰分析」がlm()と言う関数で一発で回答が出る事に驚愕した。
いや「回帰分析」自身は「屁」みたいな、演算だが、其れ相応に手間がかかるもので、1コマンド1行で、やられた日にゃ、「屁」みたいな演算が益々軽くなって「透かしっ屁」になりそうな勢いだろう。
この機械学習のサイトは、ソコソコの論理的説明をして、サンプルデータを引っ張ってきて計算結果を出して「御終い」である。「回帰分析」では、傾きと切片の数値だけである。まぁ統計情報をサマリーとして出しているが、無味乾燥でしかない。
機械学習の関係者ってのは、こんなモノかい?俺は回帰分析って言やぁランダムっぽい点と座標系に一本の線が引かれている姿を想像する。それが俺の「回帰分析」のイメージだ。
一回流れが出来てからなら「簡単」も結構だが、ライブラリー化、関数化、クラス化されるとアルゴリズムの可視性とデータのハンドリングが全く見えなくなる。
RやJupyterは、コードはスクリプトで、計算速度を稼ぐためにライブラリーはコンパイルされ、いよいよ実態は箱の中である。
いっぺんK最近値法と決定木のCでのコードを見たが、K最近値法は、実に簡単で10秒で終わったが、決定木のコードはC++で書かれて、インクルードファイルに<vector>が入っていて追うのに苦労した。
ここはそれ、捨てる神あれば拾う神ありで、「だうえ」氏のコードが頃合いが良いようで、七面倒臭いC++とは別世界の心地よさだった。
決定木の説明も実に細やかで感心したが、SVCやランダムフォレスト、アンサンブル、ロジスティック関数などの分析は載っていなかった。
ううん…残念…
だが、これは多少の傷を我が「壊れかけの蛾次郎」脳に付けてくれた。大いに為になった。
最新の画像[もっと見る]
-
 「ちうごく」が本当に戦争できるのか?溢れ出す疑問。中国海軍は機雷で全滅が保証されている。
3年前
「ちうごく」が本当に戦争できるのか?溢れ出す疑問。中国海軍は機雷で全滅が保証されている。
3年前
-
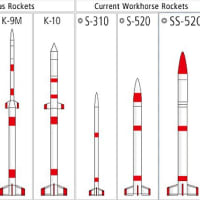 糞舐め汚い嘲賤よ…慄えて眠れ、日本の固体燃料ロケット・ラインナップは、「世界一 ぃぃぃぃぃぃいいいいいい!」スクラム・ジェット・エンジンも世界最高位技術!
3年前
糞舐め汚い嘲賤よ…慄えて眠れ、日本の固体燃料ロケット・ラインナップは、「世界一 ぃぃぃぃぃぃいいいいいい!」スクラム・ジェット・エンジンも世界最高位技術!
3年前
-
 生首が騙されて嘘言うとります。『米国レーザー兵器試験成功で戦闘機にも搭載か!艦艇からのテストは成功も戦闘機実験は可能なのか?』【ゆっくり解説・軍事News2021/12/06】
3年前
生首が騙されて嘘言うとります。『米国レーザー兵器試験成功で戦闘機にも搭載か!艦艇からのテストは成功も戦闘機実験は可能なのか?』【ゆっくり解説・軍事News2021/12/06】
3年前
-
 台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
-
 台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
-
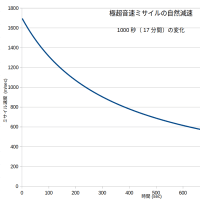
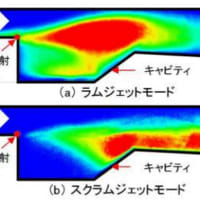 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
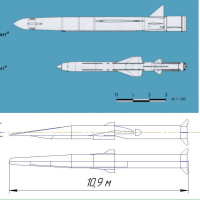 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
※コメント投稿者のブログIDはブログ作成者のみに通知されます