








Chainer,Tensorflow,Keras,Theano等は見てきたが、Caffe,Caffe2,PyTorch,Azure,Rなどは見ていないが、相応に凄いソフトのようだ。
だがScikitlearnに溺れていると、内部処理が見えなくなるので、危険だなと毎度思い、Scikitlearnを使わない人工知能のコードを読んでいる。
このPyTorchってのが、Pythonを使っている私からすれば、妙に蠱惑的なのだが、まぁ英語のPDFテキストが膨大な割に日本語の説明が少ない。
Google検索で4ページとは、全く日本の人工知能は遅れている。
まぁざーと見ると、PyTorchは自動微分とかCudaとか書いており唯一の日本語のPDFテキストはNVIDIAであった。
NVIDIAの資料は英語のPDFでも当然存在し関心の熱さを感じてしまう。
それにしても最低でも25ページ、最大のは12MB、230ページの膨大なものだ。
これほどの入れ込みようは半端じゃない。
まぁ色々やっていると、知恵の1つや2つは付くもので、まぁ「これは」こうして使うか?とかのアイデアが出てくるし、今のシステムの弱さも分かるし、何もこんなもの人工知能でやらんでも良いでしょう?と思うものもある。
長い間、人工知能の端っこにあるな?と思っていたが、このNVIDIAの入れ込みようでは、こりゃCUDA+PyTorchがGPUオペレーションのデファクトになるのか?と思ってしまう。
今の所第一世代の人工知能用のCPUだが、どうもNVIDIAのGPU+CUDAに勝つ者は居らず、今後もNVIDIAの一人勝ちが進むのだろうか?と思ってしまう。
私は画像認識ではなく画像分析を人工知能に依頼したい。
また音声認識を使い使用する事と、ロボットの頭脳としても使いたい。
最近感じるのはディープラーニングばかりが人工知能ではなく中間層の無いニューラルネットの方が現場の状況を単純だが高速に学習すると言う作業も必要だろう。
何れにしても、現在の人工知能は認識の正確さ、速さ、新しい情報の分析などの進化の流れがメインだが、アッセンブリーとしての人工知能のセットを動かすのも、そろそろ必要だろう。
最新の画像[もっと見る]
-
 「ちうごく」が本当に戦争できるのか?溢れ出す疑問。中国海軍は機雷で全滅が保証されている。
3年前
「ちうごく」が本当に戦争できるのか?溢れ出す疑問。中国海軍は機雷で全滅が保証されている。
3年前
-
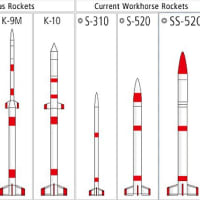 糞舐め汚い嘲賤よ…慄えて眠れ、日本の固体燃料ロケット・ラインナップは、「世界一 ぃぃぃぃぃぃいいいいいい!」スクラム・ジェット・エンジンも世界最高位技術!
3年前
糞舐め汚い嘲賤よ…慄えて眠れ、日本の固体燃料ロケット・ラインナップは、「世界一 ぃぃぃぃぃぃいいいいいい!」スクラム・ジェット・エンジンも世界最高位技術!
3年前
-
 生首が騙されて嘘言うとります。『米国レーザー兵器試験成功で戦闘機にも搭載か!艦艇からのテストは成功も戦闘機実験は可能なのか?』【ゆっくり解説・軍事News2021/12/06】
3年前
生首が騙されて嘘言うとります。『米国レーザー兵器試験成功で戦闘機にも搭載か!艦艇からのテストは成功も戦闘機実験は可能なのか?』【ゆっくり解説・軍事News2021/12/06】
3年前
-
 台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
-
 台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
台山原発事故のEDF側の内部告発。SDG'Sに大きな影響を及ぼすメカニズムが狂う!『12-04 ようやく続報が出てまいりました』【妙佛 DEEP MAX・2021/12/04】
3年前
-
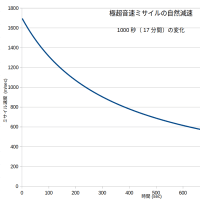
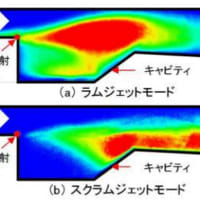 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
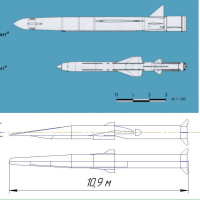 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
-
 来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
来年には極超音速ミサイル対策は可能だろう。少なくとも技術屋は極超音速ミサイル技術は見切った!またスクラム・ジェット・エンジンはJAXAと三菱重工業に存在している!騙される馬鹿文化系!
3年前
※コメント投稿者のブログIDはブログ作成者のみに通知されます