








L611 Models of Linguistic Structureの授業が後半に入り、ここまでの一般的な統計から、言語学の統計モデルと分析に入ってきました。ついに話に聞き、論文で使われているのを見、でも使ったことがなかった、使い方も分からなかったVarbrulを習うことになりました。
実際に使うのは、後継ソフトのGoldvarb2001(Windows版)です。コメントをくださる方などは社会言語学関連の方も多いようなので、ここをご覧になる方でもとっくにご存知、あるいは利用なさっている方がいるかもしれませんね。フリーソフトなのでダウンロードして使用可。google(.comのほう)でgoldvarbと入力して検索すると、いちばん最初にヒットします。オンラインマニュアルありです。念のためアドレスを。
http://www.york.ac.uk/depts/lang/webstuff/goldvarb/
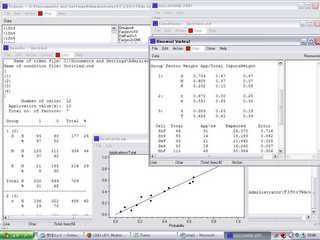
で、今日の授業で走らせることに成功。うれしかったので画像にして載せました。これはPaolillo先生が教材用に提供してくれた、LabovのNYデパート調査(Fourth floor)のデータを処理した結果です。基本のWindowの他、「データ」「分析条件」「結果」「Varbrul(いわゆるWeight Probabilityが出ます)」「散布図」などたくさんのWindowが開いています。データさえ準備できていれば、ここまではあっというま。
一つ一つのWindowを最小化できないのが不便。最小化すると、全部いっぺんに隠れます。もとがLISPという言語を使って開発されたため、独特のデータ処理操作を(ちょっとだけ)覚えなくてはいけませんが、データの分類や分析手法に改良を加えつつ何度も処理を走らせることが、とても容易に出来るようになっています。いわゆるロジスティック回帰分析をやるなら、SPSSなどの統計ソフトよりも使いやすく、解釈もしやすくて、確かに非常に強力な研究ツールのようです。さすがは、「総本山」Pennsylvania大学で永年改良されてきただけのことはある。敢えてSPSSだけで通さず、Goldvarbをカリキュラムに入れた意義が分かります。でも、社会言語学のデータに限らずどの分野のデータにも使えるようです。
詳しい使い方とモデルは先生の本を。
Paolillo, John. C. 2002. Analyzing Linguistic Variation: Statistical Models and Methods. Stanford: CSLI Publications.
この本、誤植がめちゃくちゃ多いです。英語も分かりにくい。授業と通ずるものが。今日の授業で「ロジットモデルについて、前の章で少しだけでも説明しておけばよかったと後悔してるんです」と言ってたけど、その前にまず次の版では誤植しっかり直そう、先生。。。 でもこれまた授業同様、彼の経験と洞察がつまっている本で、私は好きです。今日も、分散分析と回帰分析がどうして同じ一般線形モデルなのかとか、「切片」の意味を考えていくと「自由度」の意味が分かるとか、多次元の図を描きながら説明してくれました。Paolillo先生こういうところの切れ味がバツグンで、一生懸命聞いていると、数学<超>苦手なワタクシでも、かなり明解なイメージが見えてくる気がします。
話しがズレましたが、そういうわけで、言語研究をやってらっしゃる方はぜひ一度お試しください。ちなみに、Macバージョンはさらに便利だそうです。上記の本もそちらを使っています(基本操作はまったく同じらしい)。
実際に使うのは、後継ソフトのGoldvarb2001(Windows版)です。コメントをくださる方などは社会言語学関連の方も多いようなので、ここをご覧になる方でもとっくにご存知、あるいは利用なさっている方がいるかもしれませんね。フリーソフトなのでダウンロードして使用可。google(.comのほう)でgoldvarbと入力して検索すると、いちばん最初にヒットします。オンラインマニュアルありです。念のためアドレスを。
http://www.york.ac.uk/depts/lang/webstuff/goldvarb/
で、今日の授業で走らせることに成功。うれしかったので画像にして載せました。これはPaolillo先生が教材用に提供してくれた、LabovのNYデパート調査(Fourth floor)のデータを処理した結果です。基本のWindowの他、「データ」「分析条件」「結果」「Varbrul(いわゆるWeight Probabilityが出ます)」「散布図」などたくさんのWindowが開いています。データさえ準備できていれば、ここまではあっというま。
一つ一つのWindowを最小化できないのが不便。最小化すると、全部いっぺんに隠れます。もとがLISPという言語を使って開発されたため、独特のデータ処理操作を(ちょっとだけ)覚えなくてはいけませんが、データの分類や分析手法に改良を加えつつ何度も処理を走らせることが、とても容易に出来るようになっています。いわゆるロジスティック回帰分析をやるなら、SPSSなどの統計ソフトよりも使いやすく、解釈もしやすくて、確かに非常に強力な研究ツールのようです。さすがは、「総本山」Pennsylvania大学で永年改良されてきただけのことはある。敢えてSPSSだけで通さず、Goldvarbをカリキュラムに入れた意義が分かります。でも、社会言語学のデータに限らずどの分野のデータにも使えるようです。
詳しい使い方とモデルは先生の本を。
Paolillo, John. C. 2002. Analyzing Linguistic Variation: Statistical Models and Methods. Stanford: CSLI Publications.
この本、誤植がめちゃくちゃ多いです。英語も分かりにくい。授業と通ずるものが。今日の授業で「ロジットモデルについて、前の章で少しだけでも説明しておけばよかったと後悔してるんです」と言ってたけど、その前にまず次の版では誤植しっかり直そう、先生。。。 でもこれまた授業同様、彼の経験と洞察がつまっている本で、私は好きです。今日も、分散分析と回帰分析がどうして同じ一般線形モデルなのかとか、「切片」の意味を考えていくと「自由度」の意味が分かるとか、多次元の図を描きながら説明してくれました。Paolillo先生こういうところの切れ味がバツグンで、一生懸命聞いていると、数学<超>苦手なワタクシでも、かなり明解なイメージが見えてくる気がします。
話しがズレましたが、そういうわけで、言語研究をやってらっしゃる方はぜひ一度お試しください。ちなみに、Macバージョンはさらに便利だそうです。上記の本もそちらを使っています(基本操作はまったく同じらしい)。