










1月23日、「ビッグデータ管理入門」の後半を、NIIで聞いてきた
その内容(=表題のことをする)をメモメモのつづき
今日は、昨日作成したARFFファイル、sample.arffを基に、
決定木(J48)を行って、表示するプログラム
詳しいことは、よく分かっていないが、これでよいらしい
その内容(=表題のことをする)をメモメモのつづき
今日は、昨日作成したARFFファイル、sample.arffを基に、
決定木(J48)を行って、表示するプログラム
詳しいことは、よく分かっていないが、これでよいらしい
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Random;
import javax.swing.JFrame;
import weka.classifiers.Evaluation;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.gui.treevisualizer.PlaceNode2;
import weka.gui.treevisualizer.TreeVisualizer;
public class J48Sample {
private static final String ARFF_PATH= "sample.arff";
public static void main(String[] args) {
J48Sample app = new J48Sample();
app.analyze(ARFF_PATH);
}
private void analyze(String arffPath) {
try {
Instances data = loadData(arffPath);
if (data == null) {
return;
}
J48 tree = new J48();
String[] options = new String[1];
options[0] = "-U";
tree.setOptions(options);
tree.buildClassifier(data);
evalResult(tree, data);
showResult(tree);
} catch (Exception e) {
e.printStackTrace();
}
}
private Instances loadData(String arffPath) {
try {
Instances data = new Instances(new BufferedReader(new FileReader(arffPath)));
data.setClassIndex(data.numAttributes() - 1);
return data;
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
private void evalResult(J48 tree, Instances data) {
try {
Evaluation eval = new Evaluation(data);
eval.crossValidateModel(tree, data, 10, new Random(1));
System.out.println(eval.toSummaryString());
} catch (Exception e) {
e.printStackTrace();
}
}
private void showResult(J48 tree) {
try {
TreeVisualizer visualizer = new TreeVisualizer(null, tree.graph(), new PlaceNode2());
JFrame frame = new JFrame("Results");
frame.setSize(800, 500);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.getContentPane().add(visualizer);
frame.setVisible(true);
visualizer.fitToScreen();
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
1月23日、「ビッグデータ管理入門」の後半を、NIIで聞いてきた
その内容(=表題のことをする)をメモメモのつづき
今回は、Cassndraにデータをいれて、
そのデータを取ってきて、
Wekaの標準フォーマットARFFに落とすところのソースコード。
■お題
今、2つのCSVファイルがある。
●1つはsnps.csvで、これは、
1,ba,aa,ba,ab,ba,aa,ab,bb,ba,aa,aa,ab,・・・・
のように、IDのあとに、aa,ab,ba,bbの組み合わせが100個入っている。
(1つのaa,とか(=以下SNPと呼ぶ)は、ある箇所の遺伝情報を表現している
と思ってください)
ID+SNP1、SNP2・・・・、SNP100
で1人分。これが、10000件ある(=1万人データ)
●もう一つは、diseses.csvで、これは
1,-,-,+
2,+,-,-
3,-,-,-
:
:
のように、IDの後に3つの病気にかかったか、どうかが書かれている。
現在は、この2つしか情報がないが、今後情報は増えていく見込みである。
ただし、同じ10000人すべての情報がそろうか分からないし、
どのような情報がくるかもわからない。
●そこで、柔軟なDB構造が取れるCassandraで、保存したい。
DataKeyspaceというキースペースの中に、(RDBのDBに相当)
SNPというカラムファミリー(RDBのテーブルに相当)に格納する。
ローキー(主キーに相当)は、ID(1~10000)とし、
その中に、SNPは、SNP1、SNP2・・・SNP100をカラム名、
aa,ab,ba,bbのうちのとり得る値をカラム値とする。
さらに、それに追加して、病気についてDIS1~DIS3のカラムも追加する。
●その中から、データをとりたし、Wekaで解析したい。
今回は、SNP1,SNP2,SNP3を使い、DIS1になるかどうかを、
決定木で会席するための、Weka標準ファイルARFFを作成する。
ちなみに、ファイルの中身はこんな感じ。
@relation Sample
@attribute id numeric
@attribute SNP1 {aa,ab,ba,bb}
@attribute SNP2 {aa,ab,ba,bb}
@attribute SNP3 {aa,ab,ba,bb}
@attribute DIS {+,-}
@data
1,ba,aa,ba,-
2,bb,ab,bb,-
3,bb,bb,ab,-
4,ab,ab,ba,-
5,bb,ba,ab,-
:
(以下省略)
書き出し処理は、以下のソースのfindAllSample1だけで行っている。
■ソースコード
その内容(=表題のことをする)をメモメモのつづき
今回は、Cassndraにデータをいれて、
そのデータを取ってきて、
Wekaの標準フォーマットARFFに落とすところのソースコード。
■お題
今、2つのCSVファイルがある。
●1つはsnps.csvで、これは、
1,ba,aa,ba,ab,ba,aa,ab,bb,ba,aa,aa,ab,・・・・
のように、IDのあとに、aa,ab,ba,bbの組み合わせが100個入っている。
(1つのaa,とか(=以下SNPと呼ぶ)は、ある箇所の遺伝情報を表現している
と思ってください)
ID+SNP1、SNP2・・・・、SNP100
で1人分。これが、10000件ある(=1万人データ)
●もう一つは、diseses.csvで、これは
1,-,-,+
2,+,-,-
3,-,-,-
:
:
のように、IDの後に3つの病気にかかったか、どうかが書かれている。
現在は、この2つしか情報がないが、今後情報は増えていく見込みである。
ただし、同じ10000人すべての情報がそろうか分からないし、
どのような情報がくるかもわからない。
●そこで、柔軟なDB構造が取れるCassandraで、保存したい。
DataKeyspaceというキースペースの中に、(RDBのDBに相当)
SNPというカラムファミリー(RDBのテーブルに相当)に格納する。
ローキー(主キーに相当)は、ID(1~10000)とし、
その中に、SNPは、SNP1、SNP2・・・SNP100をカラム名、
aa,ab,ba,bbのうちのとり得る値をカラム値とする。
さらに、それに追加して、病気についてDIS1~DIS3のカラムも追加する。
●その中から、データをとりたし、Wekaで解析したい。
今回は、SNP1,SNP2,SNP3を使い、DIS1になるかどうかを、
決定木で会席するための、Weka標準ファイルARFFを作成する。
ちなみに、ファイルの中身はこんな感じ。
@relation Sample
@attribute id numeric
@attribute SNP1 {aa,ab,ba,bb}
@attribute SNP2 {aa,ab,ba,bb}
@attribute SNP3 {aa,ab,ba,bb}
@attribute DIS {+,-}
@data
1,ba,aa,ba,-
2,bb,ab,bb,-
3,bb,bb,ab,-
4,ab,ab,ba,-
5,bb,ba,ab,-
:
(以下省略)
書き出し処理は、以下のソースのfindAllSample1だけで行っている。
■ソースコード
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Iterator;
import weka.core.Attribute;
import weka.core.FastVector;
import weka.core.Instance;
import weka.core.Instances;
import weka.core.converters.ArffSaver;
import me.prettyprint.cassandra.serializers.IntegerSerializer;
import me.prettyprint.cassandra.serializers.StringSerializer;
import me.prettyprint.cassandra.service.ColumnSliceIterator;
import me.prettyprint.cassandra.service.KeyIterator;
import me.prettyprint.cassandra.service.ThriftKsDef;
import me.prettyprint.cassandra.service.template.ColumnFamilyResult;
import me.prettyprint.cassandra.service.template.ColumnFamilyTemplate;
import me.prettyprint.cassandra.service.template.ColumnFamilyUpdater;
import me.prettyprint.cassandra.service.template.ThriftColumnFamilyTemplate;
import me.prettyprint.hector.api.Cluster;
import me.prettyprint.hector.api.Keyspace;
import me.prettyprint.hector.api.beans.HColumn;
import me.prettyprint.hector.api.ddl.ColumnFamilyDefinition;
import me.prettyprint.hector.api.ddl.ComparatorType;
import me.prettyprint.hector.api.ddl.KeyspaceDefinition;
import me.prettyprint.hector.api.factory.HFactory;
import me.prettyprint.hector.api.query.SliceQuery;
/**
* Hello world!
*
*/
public class Sample {
public static String CLUSTER_NAME = "Test Cluster";
public static String DB_SERVER = "127.0.0.1";
public static String KEYSPACE_NAME = "DataKeyspace";
public static String COLUMN_FAMILY_NAME = "SNP";
static final String SNAPS_FILE_PATH= "snps.csv";
static final String DISESES_FILE_PATH= "diseses.csv";
static final String FILE_PATH= "sample.arff";
private Cluster cluster;
private KeyspaceDefinition keyspaceDef;
private Keyspace keyspace;
private ColumnFamilyTemplate<Integer, String> template;
/*
* 主処理:処理内容
*/
public static void main(String[] args) {
Sample app = new Sample();
app.prepare();
// データをCassandraに
app.insertSample(); // SNPデータ
app.updateSample(); // 病気になったかデータ追加
// Cassandra→ARFF
app.findAllSample1();
}
/*
* 初期化:クラスター取得
*/
public Sample() {
cluster = HFactory.getOrCreateCluster(CLUSTER_NAME, DB_SERVER + ":9160");
}
/*
* Cassandraアクセス準備:キースペース、カラムファミリの準備
*/
private void prepare() {
keyspaceDef = cluster.describeKeyspace(KEYSPACE_NAME);
if (keyspaceDef == null) {
KeyspaceDefinition newKeyspace = HFactory.createKeyspaceDefinition(KEYSPACE_NAME, ThriftKsDef.DEF_STRATEGY_CLASS, 1, null);
cluster.addKeyspace(newKeyspace, true);
ColumnFamilyDefinition cfDef = HFactory.createColumnFamilyDefinition(KEYSPACE_NAME, COLUMN_FAMILY_NAME, ComparatorType.BYTESTYPE);
cluster.addColumnFamily(cfDef);
}
keyspace = HFactory.createKeyspace(KEYSPACE_NAME, cluster);
template = new ThriftColumnFamilyTemplate<Integer, String>(keyspace, COLUMN_FAMILY_NAME, IntegerSerializer.get(), StringSerializer.get());
}
/*
* キースペース(DB相当)の削除
*/
private void dropKeyspace() {
cluster.dropKeyspace(KEYSPACE_NAME);
}
/*
* SNPのCSVふぁいるをCassandraへ(SNP1からSNP100まで、10000件ある)
*/
private void insertSample() {
System.out.println("----- insertSample -----");
try
{
FileReader fr = new FileReader(SNAPS_FILE_PATH);
BufferedReader br = new BufferedReader(fr);
String buf = null;
while((buf = br.readLine())!= null)
{
String cell[] = buf.split(",");
int i = Integer.parseInt(cell[0]);
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
System.out.println("key"+i+":");
for(int j = 1 ; j < cell.length;j++)
{
System.out.println("\tSNP"+j+":"+cell[j]);
updater.setString("SNP"+j, cell[j]);
}
template.update(updater);
}
br.close();
fr.close();
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* DIS(病気になったか)のCSVふぁいるをCassandraへ(SNPに追加)
*/
private void updateSample() {
System.out.println("----- updateSample -----");
try
{
FileReader fr = new FileReader(DISESES_FILE_PATH);
BufferedReader br = new BufferedReader(fr);
String buf = null;
while((buf = br.readLine())!= null)
{
String cell[] = buf.split(",");
int i = Integer.parseInt(cell[0]);
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
System.out.println("key"+i+":");
for(int j = 1 ; j < cell.length;j++)
{
System.out.println("\tdis"+j+":"+cell[j]);
updater.setString("DIS"+j, cell[j]);
}
template.update(updater);
}
br.close();
fr.close();
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* CassandraのSNP1,2,3とDIS1を、IDつけてARFFファイルへ
*/
private void findAllSample1() {
System.out.println("----- findAllSample1 -----");
FastVector attributes = new FastVector();
// IDの追加
attributes.addElement(new Attribute("id"));
// SNP1~3の追加:とり得る値はどれもaa,ab,ba,bbの4種類
FastVector SNPValues = new FastVector();
SNPValues.addElement("aa");
SNPValues.addElement("ab");
SNPValues.addElement("ba");
SNPValues.addElement("bb");
attributes.addElement(new Attribute("SNP1", SNPValues));
attributes.addElement(new Attribute("SNP2", SNPValues));
attributes.addElement(new Attribute("SNP3", SNPValues));
// DIS追加:とり得る値は+、-の2種類
FastVector DISValues = new FastVector();
DISValues.addElement("+");
DISValues.addElement("-");
attributes.addElement(new Attribute("DIS", DISValues));
// Cassandraからデータを取り出し
Instances data = new Instances("Sample", attributes, 0);
for (int i = 1; i <= 10000; ++i) {
int id = i;
ColumnFamilyResult<Integer, String> res = template.queryColumns(id);
String value = "" + res.getKey() + " : " + "SNP1=" + res.getString("SNP1") + " " + "dis1=" + res.getString("DIS1") + " " + "DIS2=" + res.getString("DIS2");
System.out.println(value);
double[] values = new double[data.numAttributes()];
values[0] = i;
values[1] = data.attribute(1).indexOfValue(res.getString("SNP1"));
values[2] = data.attribute(2).indexOfValue(res.getString("SNP2"));
values[3] = data.attribute(3).indexOfValue(res.getString("SNP3"));
values[4] = data.attribute(4).indexOfValue(res.getString("DIS1"));
data.add(new Instance(1.0, values));
}
// ARFF書き出し
try {
ArffSaver arffSaver = new ArffSaver();
arffSaver.setInstances(data);
arffSaver.setFile(new File(FILE_PATH));
arffSaver.writeBatch();
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
1月23日、「ビッグデータ管理入門」の後半を、NIIで聞いてきた
その内容(=表題のことをする)をメモメモのつづき
今回もCassandraアクセス。
前回示したソースコードを説明する。
■概要
今回は、Cassandraにアクセスするのに、
hector
https://github.com/hector-client/hector
を使う。
この場合、アクセス方法は、こんなかんじらしい。
(1)クラスターをつくる
cluster = HFactory.getOrCreateCluster(CLUSTER_NAME, DB_SERVER + ":9160");
(2)キースペースを獲得し
keyspaceDef = cluster.describeKeyspace(KEYSPACE_NAME);
キースペースがなかったら、キースペースを作成する
KeyspaceDefinition newKeyspace =
HFactory.createKeyspaceDefinition(KEYSPACE_NAME, ThriftKsDef.DEF_STRATEGY_CLASS, 1, null);
cluster.addKeyspace(newKeyspace, true);
その後カラムファミリーを作成する
ColumnFamilyDefinition cfDef =
HFactory.createColumnFamilyDefinition(KEYSPACE_NAME, COLUMN_FAMILY_NAME, ComparatorType.BYTESTYPE);
cluster.addColumnFamily(cfDef);
(3)キースペースとカラムファミリからテンプレートを作成する
keyspace = HFactory.createKeyspace(KEYSPACE_NAME, cluster);
template = new ThriftColumnFamilyTemplate<Integer, String>
(keyspace, COLUMN_FAMILY_NAME, IntegerSerializer.get(), StringSerializer.get());
(4)このテンプレートを使って、CRUDの操作を行う。
→ここまでの内容が、前回ソースの初期化Sample() と、 prepare() の処理
<HR>
■各種処理:追加
(1)ColumnFamilyUpdaterを取得する
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
(2)Updaterを使い、キーと値を設定
updater.setString("キー", "値");
(3)更新
template.update(updater);
<HR>
■各種処理:変更
(1)ColumnFamilyUpdaterを取得する
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
(2)Updaterを使い、変更箇所のキーと値を設定
updater.setString("キー", "値");
(3)更新
template.update(updater);
<HR>
■各種処理:削除
・カラム1個消す場合
template.deleteColumn(id, "カラム");
・ロー(レコード)1つ消す場合
template.deleteRow(id);
<HR>
■各種処理:検索
・ローkey値を指定する場合
ColumnFamilyResult<Integer, String> res = template.queryColumns(id);
res.getKey()
res.getString("カラム");
・キーの範囲を指定するsliceQueryというのがある。
→これを使えば、キーに値を入れてしまい、
値の範囲を検索で来る。
その内容(=表題のことをする)をメモメモのつづき
今回もCassandraアクセス。
前回示したソースコードを説明する。
■概要
今回は、Cassandraにアクセスするのに、
hector
https://github.com/hector-client/hector
を使う。
この場合、アクセス方法は、こんなかんじらしい。
(1)クラスターをつくる
cluster = HFactory.getOrCreateCluster(CLUSTER_NAME, DB_SERVER + ":9160");
(2)キースペースを獲得し
keyspaceDef = cluster.describeKeyspace(KEYSPACE_NAME);
キースペースがなかったら、キースペースを作成する
KeyspaceDefinition newKeyspace =
HFactory.createKeyspaceDefinition(KEYSPACE_NAME, ThriftKsDef.DEF_STRATEGY_CLASS, 1, null);
cluster.addKeyspace(newKeyspace, true);
その後カラムファミリーを作成する
ColumnFamilyDefinition cfDef =
HFactory.createColumnFamilyDefinition(KEYSPACE_NAME, COLUMN_FAMILY_NAME, ComparatorType.BYTESTYPE);
cluster.addColumnFamily(cfDef);
(3)キースペースとカラムファミリからテンプレートを作成する
keyspace = HFactory.createKeyspace(KEYSPACE_NAME, cluster);
template = new ThriftColumnFamilyTemplate<Integer, String>
(keyspace, COLUMN_FAMILY_NAME, IntegerSerializer.get(), StringSerializer.get());
(4)このテンプレートを使って、CRUDの操作を行う。
→ここまでの内容が、前回ソースの初期化Sample() と、 prepare() の処理
<HR>
■各種処理:追加
(1)ColumnFamilyUpdaterを取得する
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
(2)Updaterを使い、キーと値を設定
updater.setString("キー", "値");
(3)更新
template.update(updater);
<HR>
■各種処理:変更
(1)ColumnFamilyUpdaterを取得する
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
(2)Updaterを使い、変更箇所のキーと値を設定
updater.setString("キー", "値");
(3)更新
template.update(updater);
<HR>
■各種処理:削除
・カラム1個消す場合
template.deleteColumn(id, "カラム");
・ロー(レコード)1つ消す場合
template.deleteRow(id);
<HR>
■各種処理:検索
・ローkey値を指定する場合
ColumnFamilyResult<Integer, String> res = template.queryColumns(id);
res.getKey()
res.getString("カラム");
・キーの範囲を指定するsliceQueryというのがある。
→これを使えば、キーに値を入れてしまい、
値の範囲を検索で来る。
1月23日、「ビッグデータ管理入門」の後半を、NIIで聞いてきた
その内容(=表題のことをする)をメモメモのつづき
今回は、Cassandraアクセス。
hectorを使ってアクセスしている。
今回は、いただいたソースコードを貼ってみる。
(説明は次回)
とりあえず、今日はここまで。
あしたから、説明する。
その内容(=表題のことをする)をメモメモのつづき
今回は、Cassandraアクセス。
hectorを使ってアクセスしている。
今回は、いただいたソースコードを貼ってみる。
(説明は次回)
import java.util.Iterator;
import me.prettyprint.cassandra.serializers.IntegerSerializer;
import me.prettyprint.cassandra.serializers.StringSerializer;
import me.prettyprint.cassandra.service.ColumnSliceIterator;
import me.prettyprint.cassandra.service.KeyIterator;
import me.prettyprint.cassandra.service.ThriftKsDef;
import me.prettyprint.cassandra.service.template.ColumnFamilyResult;
import me.prettyprint.cassandra.service.template.ColumnFamilyTemplate;
import me.prettyprint.cassandra.service.template.ColumnFamilyUpdater;
import me.prettyprint.cassandra.service.template.ThriftColumnFamilyTemplate;
import me.prettyprint.hector.api.Cluster;
import me.prettyprint.hector.api.Keyspace;
import me.prettyprint.hector.api.beans.HColumn;
import me.prettyprint.hector.api.ddl.ColumnFamilyDefinition;
import me.prettyprint.hector.api.ddl.ComparatorType;
import me.prettyprint.hector.api.ddl.KeyspaceDefinition;
import me.prettyprint.hector.api.factory.HFactory;
import me.prettyprint.hector.api.query.SliceQuery;
/**
* Hello world!
*
*/
public class Sample {
public static String CLUSTER_NAME = "Test Cluster";
public static String DB_SERVER = "127.0.0.1";
public static String KEYSPACE_NAME = "MyKeyspace";
public static String COLUMN_FAMILY_NAME = "AccessLog";
public static String LOG_FILE = "access.log";
private Cluster cluster;
private KeyspaceDefinition keyspaceDef;
private Keyspace keyspace;
private ColumnFamilyTemplate<Integer, String> template;
public static void main(String[] args) {
Sample app = new Sample();
// app.dropKeyspace();
app.prepare();
app.insertSample();
app.findAllSample();
app.updateSample();
app.deleteSample();
app.findAllKeys();
}
public Sample() {
cluster = HFactory.getOrCreateCluster(CLUSTER_NAME, DB_SERVER + ":9160");
}
private void prepare() {
keyspaceDef = cluster.describeKeyspace(KEYSPACE_NAME);
if (keyspaceDef == null) {
KeyspaceDefinition newKeyspace = HFactory.createKeyspaceDefinition(KEYSPACE_NAME, ThriftKsDef.DEF_STRATEGY_CLASS, 1, null);
cluster.addKeyspace(newKeyspace, true);
ColumnFamilyDefinition cfDef = HFactory.createColumnFamilyDefinition(KEYSPACE_NAME, COLUMN_FAMILY_NAME, ComparatorType.BYTESTYPE);
cluster.addColumnFamily(cfDef);
}
keyspace = HFactory.createKeyspace(KEYSPACE_NAME, cluster);
template = new ThriftColumnFamilyTemplate<Integer, String>(keyspace, COLUMN_FAMILY_NAME, IntegerSerializer.get(), StringSerializer.get());
}
private void dropKeyspace() {
cluster.dropKeyspace(KEYSPACE_NAME);
}
private void insertSample() {
System.out.println("----- insertSample -----");
for (int i = 0; i < 10; ++i) {
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(i);
updater.setString("c1", "Hello" + i);
updater.setString("c2", "World" + i * 2);
updater.setString("c3", "!!" + i * i);
template.update(updater);
System.out.println("Inserted : " + i);
}
}
private void updateSample() {
System.out.println("----- updateSample -----");
for (int i = 0; i < 5; ++i) {
int id = (int) (Math.random() * 10);
ColumnFamilyUpdater<Integer, String> updater = template.createUpdater(id);
updater.setString("c3", "!!!" + id * id * id);
template.update(updater);
System.out.println("Updated : " + id);
}
}
private void deleteSample() {
System.out.println("----- deleteSample -----");
// ランダムに3つc3消す
for (int i = 0; i < 3; ++i) {
int id = (int) (Math.random() * 10);
template.deleteColumn(id, "c3");
System.out.println("Deleted : " + id + ".c3");
}
// ランダムに1つ消す
int id = (int) (Math.random() * 10);
template.deleteRow(id);
System.out.println("Deleted : " + id);
}
private void findAllSample() {
System.out.println("----- findAllSample1 -----");
for (int i = 0; i < 10; ++i) {
int id = i;
ColumnFamilyResult<Integer, String> res = template.queryColumns(id);
String value = "" + res.getKey() + " : " + "c1=" + res.getString("c1") + " " + "c3=" + res.getString("c3");
System.out.println(value);
}
}
private void findAllKeys() {
System.out.println("----- findAllKeys -----");
@SuppressWarnings("deprecation")
KeyIterator<Integer> keyIterator = new KeyIterator<Integer>(keyspace, COLUMN_FAMILY_NAME, IntegerSerializer.get());
Iterator<Integer> itr = keyIterator.iterator();
while (itr.hasNext()) {
Integer key = itr.next();
System.out.println(key);
}
}
}
|
とりあえず、今日はここまで。
あしたから、説明する。
1月23日、「ビッグデータ管理入門」の後半を、NIIで聞いてきた
その内容(=表題のことをする)をメモメモ
まずは、講義内容をメモメモ。
<<4時間目>>
列指向データベース
・RDBとの比較
RDB:行の形でまとめる
列指向:
列の形でまとめるものもある
→集約計算に強い、圧縮率が高い
追加のオーバーヘッド、行単位の操作は不得手
NoSQLにおける列指向
KVSの発展系:キーでソートされている
Cassandra
列指向データベース
ApacheProjectのひとつ
Google BigtableとAmazon Dynamoの影響
構造として
キースペース:DBにちかい
カラムファミリー:テーブルに近い
Rowキー:プライマリーキーに近い
カラムキー
非集中管理型
SPOFがない
AとP重視
ノード数に対してリニアーにあがる
ReplicationFactor:必ず○台データを持っている
Consistency Level:Read、Writeの一貫性
Quorum:2→どこまであつまったら、信頼するか?
データ設計について
何でもかけるけど、書かないことを推奨
例:セカンダリインデックス
キーの範囲で検索する
ローキーがどこからどこまで
カラムキー
データ設計について
ブログ記事
カテゴリー
記事
コメント
要件:記事に含まれるコメントをすべて取得
→記事を1つの行
コメントはすべてカラム→キーにタイムスタンプを入れてしまう
→キーにデータを格納する comment_2015012410300_title:'ABC
要件:特定のカテゴリだけ取得
方法1:RoWキーにカテゴリ名を含める
カテゴリカラムファミリを用意する
質問:
RDBだと、ER図
Cassandraはこういう検索ありきでローキー、カラムキーを考えるってこと?
→そうしないと、パフォーマンスは出ない
どう検索したいかわからない状態では、
データアクセス
CQL:SQLライクなアクセスが可能
制約がある
Indexを張っていないカラムを検索に使えない
ORが使えない
Javaからのアクセス
Hector http://hector-client.hithub.io/hector/build/html/index.html
データの読み込み
1つ
範囲指定:スライスクエリー
<<5時間目>>
なぜNoSQLが必要なのか
・データを解析するため
統計処理
機械学習
機械学習の例
・説明変数の選び方が大事
予測精度
機械学習
・データを元に規則などを学習し、導き出す
・多くは、未知データを分類するために利用
・決定木:わかりやすい
機械学習ツール
・Mahout
・WEKA→こんかいはこれ!
・RapidMiner
Knowledge Flow
プログラムから制御
Wekaが扱うファイル ARFFファイル
疾患:大きく2種類
1.遺伝によるもの
2.外的要因(紫外線など)
疾病の研究
・GWAS
・SNP(すにっぷ)
・エピジェネティックス
その内容(=表題のことをする)をメモメモ
まずは、講義内容をメモメモ。
<<4時間目>>
列指向データベース
・RDBとの比較
RDB:行の形でまとめる
列指向:
列の形でまとめるものもある
→集約計算に強い、圧縮率が高い
追加のオーバーヘッド、行単位の操作は不得手
NoSQLにおける列指向
KVSの発展系:キーでソートされている
Cassandra
列指向データベース
ApacheProjectのひとつ
Google BigtableとAmazon Dynamoの影響
構造として
キースペース:DBにちかい
カラムファミリー:テーブルに近い
Rowキー:プライマリーキーに近い
カラムキー
非集中管理型
SPOFがない
AとP重視
ノード数に対してリニアーにあがる
ReplicationFactor:必ず○台データを持っている
Consistency Level:Read、Writeの一貫性
Quorum:2→どこまであつまったら、信頼するか?
データ設計について
何でもかけるけど、書かないことを推奨
例:セカンダリインデックス
キーの範囲で検索する
ローキーがどこからどこまで
カラムキー
データ設計について
ブログ記事
カテゴリー
記事
コメント
要件:記事に含まれるコメントをすべて取得
→記事を1つの行
コメントはすべてカラム→キーにタイムスタンプを入れてしまう
→キーにデータを格納する comment_2015012410300_title:'ABC
要件:特定のカテゴリだけ取得
方法1:RoWキーにカテゴリ名を含める
カテゴリカラムファミリを用意する
質問:
RDBだと、ER図
Cassandraはこういう検索ありきでローキー、カラムキーを考えるってこと?
→そうしないと、パフォーマンスは出ない
どう検索したいかわからない状態では、
データアクセス
CQL:SQLライクなアクセスが可能
制約がある
Indexを張っていないカラムを検索に使えない
ORが使えない
Javaからのアクセス
Hector http://hector-client.hithub.io/hector/build/html/index.html
データの読み込み
1つ
範囲指定:スライスクエリー
<<5時間目>>
なぜNoSQLが必要なのか
・データを解析するため
統計処理
機械学習
機械学習の例
・説明変数の選び方が大事
予測精度
機械学習
・データを元に規則などを学習し、導き出す
・多くは、未知データを分類するために利用
・決定木:わかりやすい
機械学習ツール
・Mahout
・WEKA→こんかいはこれ!
・RapidMiner
Knowledge Flow
プログラムから制御
Wekaが扱うファイル ARFFファイル
疾患:大きく2種類
1.遺伝によるもの
2.外的要因(紫外線など)
疾病の研究
・GWAS
・SNP(すにっぷ)
・エピジェネティックス
「声優の名前の勘違い」が大炎上で、らしい
はるかぜちゃん、ツイッターアカウントを削除 「声優の名前の勘違い」が大炎上
http://www.j-cast.com/2015/01/22225928.html
はるかぜちゃん、ツイッターアカウントを削除 「声優の名前の勘違い」が大炎上
http://www.j-cast.com/2015/01/22225928.html
前の、「ビッグデータ管理入門」の話のつづき。
今回は、MongoDBのサンプル。
・前提:Mavenインストール
・Gitからデータを落としてくる
・Maven実行
・プロジェクトにIMPORT
は、
PostgreSQLのhstore・JSONサンプル
http://blog.goo.ne.jp/xmldtp/e/5b4f8a2bd4087c6239f5bc0ff19dfa23
と同じなので省略。ソースコードのみ。
■ソースコード
package jp.topse.nosql.mongodb;
import java.io.BufferedReader;
import java.io.FileReader;
import java.net.UnknownHostException;
import java.sql.Statement;
import java.util.Collection;
import java.util.Set;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBCursor;
import com.mongodb.DBObject;
import com.mongodb.MongoClient;
import com.mongodb.util.JSON;
/**
* Hello world!
*
*/
public class App {
public static String DB_SERVER = "127.0.0.1";
public static String DB_NAME = "mydb";
public static String COLLECTION_NAME = "log";
public static void main(String[] args) {
kadai1(args);
kadai2(args);
}
/*
* Access Logのうち、targetがindex.htmlのものをカウントする
*/
public static void kadai2(String[] args) {
MongoClient client;
try {
client = new MongoClient(DB_SERVER, 27017);
DB db = client.getDB(DB_NAME);
DBCollection collection = db.getCollection(COLLECTION_NAME);
BasicDBObject doc = new BasicDBObject("target", "index.html");
System.out.println(collection.count(doc));
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* access.logファイルの中身を、MongoDBに格納する
*/
public static void kadai1(String[] args) {
MongoClient client;
try {
client = new MongoClient(DB_SERVER, 27017);
DB db = client.getDB(DB_NAME);
DBCollection collection = db.getCollection(COLLECTION_NAME);
// Collection内のデータをクリア
clearCollection(collection);
FileReader fr = new FileReader("access.log");
BufferedReader br = new BufferedReader(fr);
String buf;
while((buf = br.readLine()) != null)
{
// アクセス先とりふぁらを,で分ける
String cell[] = buf.split(",");
if ( ( cell.length == 0 ) || (cell[0].length() == 0))
{
continue;
}
// アクセス先とパラメータを?で分ける
String para[] = cell[0].split("\?");
BasicDBObject doc = new BasicDBObject("target", para[0]);
if ( cell.length >= 2)
{
doc.append("referer", cell[1]);
}
// パラメータリストを作成する
if ( para.length >= 2 )
{
// パラメータを&で分ける
String list[] = para[1].split("&");
BasicDBObject indoc=null;
for(int i = 0 ; i < list.length ; i ++)
{
// =でキーと値に分ける
String kv[] = list[i].split("=");
if (i == 0 )
{
indoc = new BasicDBObject(kv[0], kv[1]);
}
else
{
indoc.append(kv[0], kv[1]);
}
}
// {name: 'xyz', inner: {innder-key: 'innver-value'}}
doc.append("parameter", indoc);
}
// コレクションに追加
collection.insert(doc);
}
br.close();
fr.close();
//追加内容を表示する
DBCursor cursor = collection.find();
while (cursor.hasNext()) {
DBObject obj = cursor.next();
Set<String> keys = obj.keySet();
for (String key : keys) {
System.out.println(key + ":" + obj.get(key).toString());
}
}
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// コレクションデータ削除
public static void clearCollection(DBCollection collection) {
collection.remove(new BasicDBObject());
}
}
|
コメント中、コレクションとうのは、RDBのテーブルに相当する
(が、RDBのテーブルと違い、構造は決まっていない)
コレクションはDBに所属し(これはRDBといっしょ)
コレクションは、オブジェクトをもつ
(オブジェクト=RDBの1レコードに相当)
「文章を書くのが苦手です。どうしたらうまくなりますか?」 村上春樹の回答に激震が走った!!
http://netgeek.biz/archives/28220
ちなみに答えは(以下太字は上記サイトからの引用、または孫引き)
文章を書くというのは、女の人を口説くのと一緒で、ある程度は練習でうまくなりますが、基本的にはもって生まれたもので決まります。まあ、とにかくがんばってください。
おおおお・・・
ってことは、
「プログラムを書くのが苦手です。どうしたらうまくなりますか」?
と村上春樹氏に聞いたとしたら…
プログラムを書くというのは、女の人を口説くのと一緒で、
ある程度は練習でうまくなりますが、
基本的にはもって生まれたもので決まります。
まあ、とにかくがんばってください。
となるのだろうか?
た、たしかに・・・絶望的な回答だ・・・
そのあと、上記サイトでは
ニワトリはいくら努力しても空を飛べないということなのだろう。
冷たい回答にも思えるが、これは真理なのかもしれない。
と追い打ちをかけるのだが・・・・そうなのかもしれない。
結局は
なにかとんでもなく恐ろしいものを見てしまった気分だ。
これが自らの仕事に誇りを持つ厳しいプロの世界
ということなのだろう。
前に、「ビッグデータ管理入門」の話を書いたけど、
そこで行った、PostgreSQL,MongoDBのデモについて
まず、PostgreSQLのhstore・JSONサンプルデモについてメモメモ
■前提:Mavenインストール
実習はすでにMavenがインストールされていた環境で行ったので、
必要なかったけど、家や会社でやる場合は、まずはMavenからいれないと
いけない。
Mavenのインストールは
maven3 (3.2.x) インストール手順 (Windows)
http://weblabo.oscasierra.net/install-maven-32-windows/
にあるとおり。
(1)Download Apache Maven 3.2.5にいって、
Mavenのzipをダウンロード
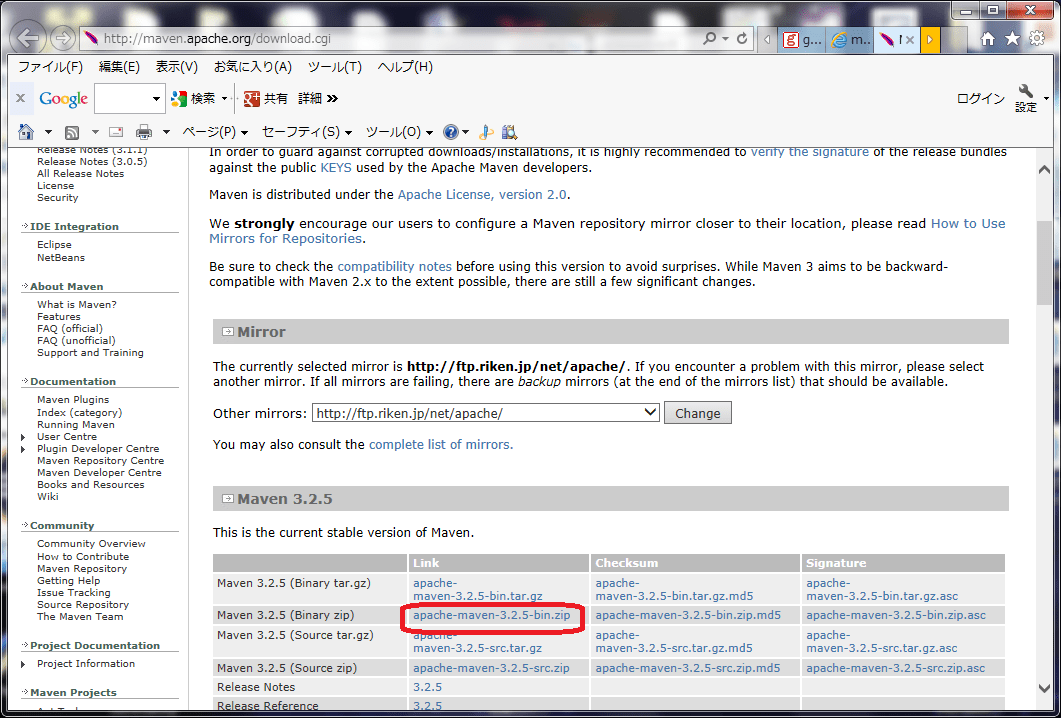
(2)それを解凍して、どこか適当なところにおく
(3)システムの環境設定で、(2)に置いたフォルダの下のbinに
パス(PATH)を通る
なお、Javaはインストールされていて、JAVA_HOMEは設定されている、eclipseはあるものとします。
■Gitからデータを落としてくる
eclipseのWindow→Open Perspective→Otherから、Gitを選んで、
Gitのclone a git repository でクローンを作る。
今回は、PostgreSQLのサンプルをクローンする
ここで以下のMaven実行をしたけど、これをプロジェクトにIMPORTしてから
Mavenしても、大丈夫な気がします。
■Maven実行
コマンドプロンプトを起動し、
上記Gitのプロジェクトのファイルのあるところまでいって、
mvn eclipse:eclipseとすると、依存性を解決して、ライブラリが出来てくれる。
ちなみに、pom.xmlはこんなかんじ。
■プロジェクトにIMPORT
さっき書いたように、GitをプロジェクトにImport
■ソース
あってるかどうかわかんないけど、こんな感じ。
そこで行った、PostgreSQL,MongoDBのデモについて
まず、PostgreSQLのhstore・JSONサンプルデモについてメモメモ
■前提:Mavenインストール
実習はすでにMavenがインストールされていた環境で行ったので、
必要なかったけど、家や会社でやる場合は、まずはMavenからいれないと
いけない。
Mavenのインストールは
maven3 (3.2.x) インストール手順 (Windows)
http://weblabo.oscasierra.net/install-maven-32-windows/
にあるとおり。
(1)Download Apache Maven 3.2.5にいって、
Mavenのzipをダウンロード
(2)それを解凍して、どこか適当なところにおく
(3)システムの環境設定で、(2)に置いたフォルダの下のbinに
パス(PATH)を通る
なお、Javaはインストールされていて、JAVA_HOMEは設定されている、eclipseはあるものとします。
■Gitからデータを落としてくる
eclipseのWindow→Open Perspective→Otherから、Gitを選んで、
Gitのclone a git repository でクローンを作る。
今回は、PostgreSQLのサンプルをクローンする
ここで以下のMaven実行をしたけど、これをプロジェクトにIMPORTしてから
Mavenしても、大丈夫な気がします。
■Maven実行
コマンドプロンプトを起動し、
上記Gitのプロジェクトのファイルのあるところまでいって、
mvn eclipse:eclipseとすると、依存性を解決して、ライブラリが出来てくれる。
ちなみに、pom.xmlはこんなかんじ。
■プロジェクトにIMPORT
さっき書いたように、GitをプロジェクトにImport
■ソース
あってるかどうかわかんないけど、こんな感じ。
package jp.topse.nosql.pgsql;
import java.io.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
import org.codehaus.jackson.JsonParseException;
import org.codehaus.jackson.map.JsonMappingException;
import org.codehaus.jackson.map.ObjectMapper;
import org.postgresql.util.PGobject;
/**
* Hello world!
*
*/
public class App {
public static final String DRIVER = "org.postgresql.Driver";
public static final String DB_SERVER = "127.0.0.1";
public static final String DB_NAME = "test";
public static final String DB_USER = "root";
public static final String DB_PASS = "password";
public static final String TABLE_NAME_1 = "log_1";
public static final String TABLE_NAME_2 = "log_2";
public static void main(String[] args) {
Connection con = createConnection();
if (con == null) {
return;
}
testHstore(con);
testHcount(con);
testHKadai3(con);
testJson(con);
testJcount(con);
testJKadai3(con);
}
/*
* ターゲットがindex.html,パラメータx=1(hstore)
*/
public static void testHKadai3(Connection con)
{
try
{
Statement statement = con.createStatement();
String query = "SELECT COUNT(*) as kensu from "+ TABLE_NAME_1 +" where attributes->'target' = 'index.html' AND attributes->'parameter' = 'x=1'";
ResultSet rs = statement.executeQuery(query);
while(rs.next())
{
System.out.println(rs.getInt("kensu"));
}
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* ターゲットがindex.html (hstore)
*/
public static void testHcount(Connection con)
{
try
{
Statement statement = con.createStatement();
String query = "SELECT COUNT(*) as kensu from "+ TABLE_NAME_1 +" where attributes->'target' = 'index.html'";
ResultSet rs = statement.executeQuery(query);
while(rs.next())
{
System.out.println(rs.getInt("kensu"));
}
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* データ入力 (hstore)
*/
public static void testHstore(Connection con) {
try {
FileReader fr = new FileReader("access.log");
BufferedReader br = new BufferedReader(fr);
String buf;
while((buf = br.readLine()) != null)
{
Statement statement = con.createStatement();
String query = "INSERT INTO " + TABLE_NAME_1 + " (datetime, attributes) " + " VALUES " + " (NOW(), '";
String cell[] = buf.split(",");
String para[] = cell[0].split("\?");
query = query + " target => \"" + para[0] + "\",";
if ( cell.length >= 2)
{
query = query + " referer => \"" + cell[1] + "\",";
}
if ( para.length >= 2)
{
query = query + " parameter => \"" + para[1] + "\",";
}
query = query + "');";
statement.executeUpdate(query);
}
br.close();
fr.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
PreparedStatement statement = con.prepareStatement("SELECT * FROM " + TABLE_NAME_1);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
Map<String, Object> map = (HashMap<String, Object>) resultSet.getObject(3);
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/*
* ターゲットがindex.html,パラメータx=1(JSON)
*/
public static void testJKadai3(Connection con)
{
try
{
Statement statement = con.createStatement();
String query = "SELECT COUNT(*) as kensu from "+ TABLE_NAME_2 +" where attributes->>'target' = 'index.html' AND attributes->'parameter'->>'x'='1'";
ResultSet rs = statement.executeQuery(query);
while(rs.next())
{
System.out.println(rs.getInt("kensu"));
}
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* ターゲットがindex.html (JSON)
*/
public static void testJcount(Connection con)
{
try
{
Statement statement = con.createStatement();
String query = "SELECT COUNT(*) as kensu from "+ TABLE_NAME_2 +" where attributes->>'target' = 'index.html'";
ResultSet rs = statement.executeQuery(query);
while(rs.next())
{
System.out.println(rs.getInt("kensu"));
}
}
catch(Exception e)
{
e.printStackTrace();
}
}
/*
* データ入力 (JSON)
*/
public static void testJson(Connection con) {
try {
FileReader fr = new FileReader("access.log");
BufferedReader br = new BufferedReader(fr);
String buf;
while((buf = br.readLine()) != null)
{
Statement statement = con.createStatement();
String query = "INSERT INTO " + TABLE_NAME_2 + " (datetime, attributes) " + " VALUES " + " (NOW(), '{";
String cell[] = buf.split(",");
String para[] = cell[0].split("\?");
query = query + " \"target\":\"" + para[0] + "\"";
if ( cell.length >= 2)
{
query = query + ",";
query = query + " \"referer\":\"" + cell[1] + "\"";
}
if ( para.length >= 2)
{
query = query + ",";
query = query + " \"parameter\":{";
String list[] = para[1].split("&");
int cflg = 0;
for(int i = 0 ; i < list.length ; i ++)
{
String kv[] = list[i].split("=");
if (kv.length < 2)
{
continue;
}
if (cflg == 0 )
{
cflg = 1;
}
else
{
query = query + ",";
}
query = query + "\""+kv[0]+"\":"+kv[1];
}
query = query + "}";
}
query = query + "}')";
System.out.println(query);
statement.executeUpdate(query);
}
br.close();
fr.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
PreparedStatement statement = con.prepareStatement("SELECT * FROM " + TABLE_NAME_2);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
PGobject object = (PGobject) resultSet.getObject(3);
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> map = mapper.readValue(object.getValue(), Map.class);
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
} catch (SQLException e) {
e.printStackTrace();
} catch (JsonParseException e) {
e.printStackTrace();
} catch (JsonMappingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* コネクション生成(共通)
*/
public static Connection createConnection() {
try {
String url = "jdbc:postgresql://" + DB_SERVER + "/" + DB_NAME;
Class.forName(DRIVER);
return DriverManager.getConnection(url, DB_USER, DB_PASS);
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
return null;
}
}
}
|
このまえ
JavaMailによるメールの送信について
を書いたので、対称性として
Javaによるメールの受信について
を書いてみる。
といっても、いがぴょんさんの
http://www.igapyon.jp/igapyon/diary/2007/ig070905.html
を写しているような感じなんだけど。。。こんなかんじ
import java.util.Properties;
import javax.mail.Address;
import javax.mail.AuthenticationFailedException;
import javax.mail.Authenticator;
import javax.mail.Folder;
import javax.mail.Message;
import javax.mail.MessagingException;
import javax.mail.NoSuchProviderException;
import javax.mail.PasswordAuthentication;
import javax.mail.Session;
import javax.mail.Store;
import javax.mail.Message.RecipientType;
import javax.mail.internet.InternetAddress;
/**
* シンプルなメール受信サンプル。
*/
public class SimpleRecvMail {
public static void main(final String[] args) {
System.out.println("メール受信: 開始");
new SimpleRecvMail().process();
System.out.println("メール受信: 終了");
}
public void process() {
final Properties props = new Properties();
// 基本情報。ここでは Gooメールへの接続例を示します。
props.setProperty("mail.pop3.host", "pop.mail.goo.jp");
props.setProperty("mail.pop3.port", "110");
// タイムアウト設定
props.setProperty("mail.pop3.connectiontimeout", "60000");
props.setProperty("mail.pop3.timeout", "60000");
// SSL関連設定
props.setProperty("mail.pop3.socketFactory.class", "javax.net.ssl.SSLSocketFactory");
props.setProperty("mail.pop3.socketFactory.fallback", "false");
props.setProperty("mail.pop3.socketFactory.port", "995");
final Session session = Session.getInstance(props, new Authenticator() {
protected PasswordAuthentication getPasswordAuthentication() {
// メールアドレスとパスワードを入れる
return new PasswordAuthentication("XXXXXXXXXXXXXXX@Xmail.goo.ne.jp", "mypassword");
}
});
// デバッグを行います。標準出力にトレースが出ます。
session.setDebug(true);
Store store = null;
try {
try {
store = session.getStore("pop3");
} catch (NoSuchProviderException e) {
System.out.println("メール受信: 指定プロバイダ[pop3]の取得に失敗しました。"
+ e.toString());
return;
}
try {
store.connect();
} catch (AuthenticationFailedException e) {
System.out.println("メール受信: サーバ接続時に認証に失敗しました。" + e.toString());
return;
} catch (MessagingException e) {
System.out.println("メール受信: サーバ接続に失敗しました。" + e.toString());
return;
}
Folder folder = null;
try {
try {
// INBOXは予約語です。
folder = store.getFolder("INBOX");
} catch (MessagingException e) {
System.out.println("メール受信: INBOXフォルダ取得に失敗しました。"
+ e.toString());
return;
}
try {
folder.open(Folder.READ_ONLY);
} catch (MessagingException e) {
System.out
.println("メール受信: フォルダオープンに失敗しました。" + e.toString());
return;
}
// メッセージ一覧を取得
try {
final Message messages[] = folder.getMessages();
for (int index = 0; index < messages.length; index++) {
final Message message = messages[index];
// このAPI利用範囲であれば TOPコマンド止まりで、RETRコマンドは送出されない。
System.out.println("Subject: " + message.getSubject());
System.out.println(" Date: " + message.getSentDate().toString());
// TODO 0番目の配列アクセスをおこなっている点に注意。
final InternetAddress addrFrom = (InternetAddress) message.getFrom()[0];
System.out.println(" From: " + addrFrom.getAddress());
// MimeUtility.decodeText(addrFrom.getPersonal())
// To: を表示。
final Address[] addrsTo = message
.getRecipients(RecipientType.TO);
for (int loop = 0; loop < addrsTo.length; loop++) {
final InternetAddress addrTo = (InternetAddress) addrsTo[loop];
System.out.println(" To: " + addrTo.getAddress());
}
// Cc:は割愛
// なお、例えば message.getContentを呼び出すと RETRコマンドが送出される。
try {
// RETRコマンドを送出
System.out.println(message.getContent());
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (MessagingException e) {
System.out.println("メール受信: メッセージ取得に失敗しました。" + e.toString());
return;
}
} finally {
if (folder != null) {
try {
folder.close(false);
} catch (MessagingException e) {
System.out.println("メール受信: フォルダクローズに失敗しました。"
+ e.toString());
}
}
}
} finally {
if (store != null) {
try {
store.close();
} catch (MessagingException e) {
System.out.println("メール受信: サーバ切断に失敗しました。" + e.toString());
}
}
}
}
}
|
ほぼうつしただけだけど、これで、(メールアドレスとパスワード書きかえて)
Gooメールが見れた!
1月18日、「ビッグデータ管理入門」の前半を、NIIで聞いてきた
その内容をメモメモ
まずは、講義内容をメモメモ。
<HR>
内容:データ管理手法
NoSQL
RDB(Postgre Hstore)
ドキュメント指向(MongoDB)
列指向(Cassandra)
第一回~第4回
・ビッグデータの概念とデータ管理手法
・RDB
・ドキュメント指向
・列指向
第5回~第8回
・ゲノム解析(病気判定、リスク、weka)
ビッグデータの概念と管理手法
ビッグデータとは
データ管理の要件
ビッグデータとは
定義1:大容量データ:電気代だけでも大変!
定義2:3つのV
→何かわからないデータから、何かを導く出す
ビッグデータの課題
収集、
●取捨選択、
●保管、
●検索、
共有、
転送
解析
可視化
→●が今回の範囲
データ管理に対する用件
試行錯誤のサポートが必要
スペシャリストのモデル化+スペシャリストが見落としているところ
CAP定理
・分散システムに関する定理
・以下の3つは同時には成り立たない
Consistency 一貫性
Availability 可用性
Patition-Tolerance 分断体制
APが満たされる→一貫性X
CPが満たされる→アベイラビリティX
CAが満たされる→分断されるとX
リレーショナルデータベース
メリット:モデルが直感的
デメリット:柔軟性、スケーラビリティ
RDBは、一貫性を重視
ビッグデータは製品依存(Oracleはできるとか)
スパース:無駄なカラムを作ってしまう
NoSQLによるデータ管理
Not Only SQL
特徴 柔軟なスキーマ
スケーラビリティを確保しやすい
データの結合がないものが多い
種類
・ドキュメント MongoDB,CouchDB
・KVS(key Value Store) Dynamo
・列指向 Cassandra HBase
・グラフ指向 Neo 4J
ドキュメント指向
ドキュメントという単位でデータを管理
→各ドキュメントが独立
パフォーマンスはやや劣る
KVS
単純なので早い memcached KyotoCabinet
列指向
Google Big Tableに基づいた管理手法
Cassandra HBase
カラムファミリー、ロー、カラム(キーと値)
ディスクの使用効率がよい。検索不得手
グラフ指向
MongoDBのほうが設計しやすい
Cassandraはキーの名前、列の設計が難しい
Cassandra CQL
MongoDB Javascript
取捨選択、保管、検索は3つをすべてNoSQLでやる必要はない
<<2時間目>> RDBにおおけるビッグデータの扱い方
・データ管理に対する用件
ビッグデータ解析
スケーラビリティ
試行錯誤のサポートが重要
RDBにおけるスケールアップ レプリケーション
→単一障害店をもつ、
Writeの負荷→ノードのスケールアップ(サーバー増強):コストの問題
Google F1 分散データベースの仕組み
OoODE クエリの並列発行
柔軟なデータ構造
スキーマに基づくテーブルにデータ格納
可変なデータの扱い方
リレーションモデルの工夫
EAV Entity-Attribute Value
利点 RDBの一般的な機能
欠点 汎用的なクエリを書きにくい
階層構造を扱いにくい
→隣接リストモデル、入れ子集合モデル
PostgreSQL hStore,Json
Oracle/MySQL パフォーマンスのため
hstore key-valueのペア集合を格納
Json JSON形式のデータを格納
拡張機能の有効化 CREATE EXTENTION hstore必要
■hstore
テーブルの作成
CREATE TABLE logs(
id SERIAL PRIMARY KEY,
datetime TIMESTAMP,
attribute hstore
);
データの挿入
INSERT INTO logs
(datetime,attributes)
VALUES
(NOW(),
'target => "index.html",
referer => "http://google.com",
parameter=> "x=1"');
データの検索
SELECT * FROM logs WHERE attributes?'target';
(資料にないが、課題にあったもの)
SELECT COUNT(*) as kensu from logs where attributes->'target' = 'index.html';
■JSON
テーブル作成
CREATE TABLE logs2 (
id SERIAL PRIMARY KEY,
datetime TIMESTAMP,
attributes json
);
データ挿入
INSERT INTO
logs2 (datetime,attributes)
VALUES
(NOW(),
'{"tagret":"index.html",
"referer":"http://google.com",
"paramater":{"x":1}}');
データの検索
SELECT * from logs2 WHERE attributes->>'target'='inex.html';
(資料にないが、課題にあったもの)
SELECT COUNT(*) as kensu from logs2 where attributes->>'target' = 'index.html' AND attributes->'parameter'->>'x'='1'";
■操作
・JDBCドライバで操作できる
・HStoreはHashMapとして扱える
→古いJDBCドライバはPgobjectになる
・JSONはPGobjectとして扱える
→JSONは外部ライブラリ(本講義ではJackson)を利用
■演習のやりたか
(1)eclipseを立ち上げる
(2)window→Open パースペクティブ
(3)other→gitを選択
(4)gitのパースペクティブで、git cloneを選ぶ
(5)出てきたダイアログでURIに指定のURLを入れる
(6)コマンドプロンプトで、落としてきたフォルダにいく(CD)
(7)mvn eclipse:eclipse
(8)インポートする
general→existing project into workspace
(7)で作ったところ指定
<<3時間目>> Mongo
ドキュメント指向データベース
ドキュメント単位でデータ格納
フォーマットが決まっている:XML,JSON,YAML・・・
MongoDB
・オープンソース
・C++
・ゲームなどで
JSON形式の格納
内部的にはBSON(バイナリーJSON)
スキーマレス
Mongo
高速度
インデックスを使ったデータの参照が可能
高可用性
自動的なフェイルオーバー
レプリケーション
自動的なスケーリング
自動シャーディング
→シャードキーをどう決めるかが重要
シャードキー決め方
レンジベース
ハッシュ関数で
→スプリッター、バランサー
データのモデリング
JOINできない
→ドキュメント埋め込み、ドキュメント参照
コマンドラインからの使用
mongo
show dbs;
use mydb;
show collections;
テーブルに相当するのが、コレクション
db.testData.find();
testDataコレクションの中身を表示
Javaからの制御例
Mongo mongo = new Mongo(host poro);
DB db monogo= mongo.getDB(dbname);
DBCollection collection = db.getCollection("accessLog");
BasicDBObject doc = new BasicDBObject("target", "index.html");
System.out.println(collection.count(doc));
そうそう、1月16日にウェアラブルExpoを東京ビッグサイトにいって
見てきたんだけど・・・
ウェアラブルExpoの展示は少ないというか、そもそも
東側:ネプコン(半導体、エレクトロニクス関係)、照明、ウェアラブル
西側:Automotive World(自動車関係)
ってことで(会場案内)、ウェアラブルExpoは東側の本の一部地域。
音声認識が多かったような気がする。あとは、想像つくようなウェアラブル
むしろ、目新しかったのは、Automotive Worldのほう。
コネクテッドカーということで、(説明が終わった後で行ったので、資料しか
もらえなかったけど)、車載CANデータ・クラウドシステム構築サービス
とかいうのが、ZMPとか言うところから出てた。
簡単だけど、そんなかんじ。
見てきたんだけど・・・
ウェアラブルExpoの展示は少ないというか、そもそも
東側:ネプコン(半導体、エレクトロニクス関係)、照明、ウェアラブル
西側:Automotive World(自動車関係)
ってことで(会場案内)、ウェアラブルExpoは東側の本の一部地域。
音声認識が多かったような気がする。あとは、想像つくようなウェアラブル
むしろ、目新しかったのは、Automotive Worldのほう。
コネクテッドカーということで、(説明が終わった後で行ったので、資料しか
もらえなかったけど)、車載CANデータ・クラウドシステム構築サービス
とかいうのが、ZMPとか言うところから出てた。
簡単だけど、そんなかんじ。
もし、グローバル化しているなら、全世界は均質なはずだかから、
移民はいっぱいいて、
どこの国でも、
イスラム教に対して同じように感じるし(侮辱している⇔表現の自由なんて議論はおこらない)、
キリスト教に対しても同じように感じるはずだ!
っていう結論になる(ここまでは言ってなかったけど)
日立 Prowise Business Forum in Tokyo 第80回
ベストセラー「世界の経営学者はいま何を考えているのか」の入山章栄氏が語る!
なぜ日本企業の「グローバル化」は加速しないのか!?
~求められる国際化戦略とは~
を聞いてきたので、その内容をメモメモ
■世界の経営学から見る日本企業国際化への視座
世界はどれくらいグローバル化しているか?
→0、1ではなく、連続的に鎖国からグローバル化まで変化する
世界的には、鎖国より
→もし、グローバル化してるなら、移民とかもっと多いはず!
→実際には、セミグローバリゼーション
世界にグローバル企業はどれくらいあるか
欧州、アジア、北米とわけて、
自分が所属するエリアが50%以下、
他エリアから20%以上稼いでいる企業は
大手360社中、9社
→実際にはRegional Specific Advantage
グローバル人材は育成可能?
統合による効率化と
各国への違いに適応?
→ではどうするか?
・AAAフレームワーク:3タイプのマネージャー
Agglomeration(Functional Manager)
Arbitrage(Business Manager)
Adaptation(Country Manager)
(講演資料にある、スパイキーな国際化の説明はなかった・・時間切れ)
■グローバル企業が競争優位を創出する戦略とは
・IBM「The Customer-activated Enterprise」から
重要なもの:全体
1位 テクノロジー
2位 市場の変化
:
7位 グローバル化
日本
1位 テクノロジー
2位 市場の変化
3位 グローバル化
(ここで話の流れ途切れる)
コミュニケーション大切だよね
活文いいよ
(ごめん、このあと、事例になったんだけど、ここで帰ってしまった・・・)
■所感
・世界は、日本ほど、あんまりグローバル化には期待していない
・日立的には、グローバル化には、活文らしい?
移民はいっぱいいて、
どこの国でも、
イスラム教に対して同じように感じるし(侮辱している⇔表現の自由なんて議論はおこらない)、
キリスト教に対しても同じように感じるはずだ!
っていう結論になる(ここまでは言ってなかったけど)
日立 Prowise Business Forum in Tokyo 第80回
ベストセラー「世界の経営学者はいま何を考えているのか」の入山章栄氏が語る!
なぜ日本企業の「グローバル化」は加速しないのか!?
~求められる国際化戦略とは~
を聞いてきたので、その内容をメモメモ
■世界の経営学から見る日本企業国際化への視座
世界はどれくらいグローバル化しているか?
→0、1ではなく、連続的に鎖国からグローバル化まで変化する
世界的には、鎖国より
→もし、グローバル化してるなら、移民とかもっと多いはず!
→実際には、セミグローバリゼーション
世界にグローバル企業はどれくらいあるか
欧州、アジア、北米とわけて、
自分が所属するエリアが50%以下、
他エリアから20%以上稼いでいる企業は
大手360社中、9社
→実際にはRegional Specific Advantage
グローバル人材は育成可能?
統合による効率化と
各国への違いに適応?
→ではどうするか?
・AAAフレームワーク:3タイプのマネージャー
Agglomeration(Functional Manager)
Arbitrage(Business Manager)
Adaptation(Country Manager)
(講演資料にある、スパイキーな国際化の説明はなかった・・時間切れ)
■グローバル企業が競争優位を創出する戦略とは
・IBM「The Customer-activated Enterprise」から
重要なもの:全体
1位 テクノロジー
2位 市場の変化
:
7位 グローバル化
日本
1位 テクノロジー
2位 市場の変化
3位 グローバル化
(ここで話の流れ途切れる)
コミュニケーション大切だよね
活文いいよ
(ごめん、このあと、事例になったんだけど、ここで帰ってしまった・・・)
■所感
・世界は、日本ほど、あんまりグローバル化には期待していない
・日立的には、グローバル化には、活文らしい?





