








AITCオープンラボ
「R言語で始めよう、データサイエンス(ハンズオン勉強会)
〜機械学習・データビジュアライゼーション事始め〜」
に行ってきた!その内容のうち、(順番違うけど)ビジュアライゼーションをメモメモ
(基礎、機械学習、ビジュアライゼーション、Javascript連携と話は続く)
なお、この講義の基礎、機械学習、ビジュアライゼーション編は
http://www.slideshare.net/yasuyukisugai/r-28544592
の内容に沿って行われました。
(ソースプログラムはそのサイトより引用)
ビジュアライゼーション
ggplot2を使う
install.packages("ggplot2")
library(ggplot2)
# qplotクイックプロット
qplot(data=iris, x=Petal.Length, y=Petal.Width)
# 色分け:凡例つき
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species)
# 形で変える
qplot(data=iris, x=Petal.Length, y=Petal.Width, shape=Species)
# 大きさ
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species, size=Sepal.Length)
#層を重ねる(回帰曲線を重ねる)
qplot(data=iris, x=Petal.Length, y=Petal.Width)+stat_smooth()
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species)+ stat_smooth()
#ヒストグラム
qplot(data=iris, x=Petal.Length, geom="histogram")
qplot(data=iris, x=Petal.Length, geom="histogram", fill=Species)
#密度グラフ
qplot(data=iris, x=Petal.Length, geom="density")
#半透明
qplot(data=iris, x=Petal.Length, geom="density", fill=Species, alpha=0.3)
●台風の軌道
データ
http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/besttrack.html
フォーマット
http://homepage3.nifty.com/typhoon21/general/bst-format.html
地図 maps
install.packages("maps")
library(maps)
#緯度経度
map(xlim=c(121, 155), ylim=c(20, 50))
#描画情報も取得できる
#データ取り込み
bst<-readLines('http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/Besttracks/bst2013.txt')
View(bst)
#ヘッダー(はじめが66666)を抜き出す
header <- read.table(textConnection(bst[grep("^66666", bst)]))
View(header)
#レコード部分(それ以外)を抜き出す
record<-read.table(textConnection(bst[-grep("^66666", bst)]),fill=TRUE)
#行の長さが違うので、入らないところカット
record<-record[!is.na(record[,7]),]
View(record)
#必要なところを採ってくる
header<-header[ , c(3,4,8)]
names(header) <- c("NROW", "TC_NO", "NAME")
View(header)
record<-record[ , c(1,3:7)]
names(record) <- c("DATE_TIME", "GRADE", "LAT", "LON", "HPA", "KT")
View(record)
#台風の識別番号をつける
record$TC_NO <- rep(header$TC_NO, header$NROW)
View(record)
#台風の識別番号をもとに結合
data <- merge(header, record, by = "TC_NO")
View(data)
#元データが10倍されているので、値変換transform
data <- transform(data, LAT = LAT / 10, LON = LON / 10)
View(data)
#ここまでで、データ処理終わり、あとはビジュアライゼーション
#範囲確認
range_lon<-range(data$LON)
range_lat<-range(data$LAT)
range_lon
range_lat
#座標パスXYだけを取得
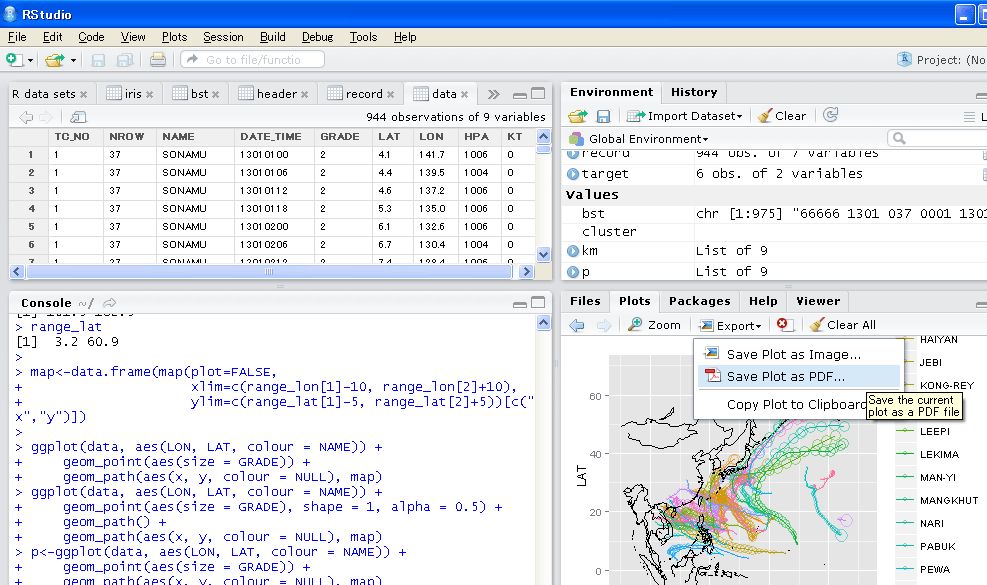
map<-data.frame(map(plot=FALSE,
xlim=c(range_lon[1]-10, range_lon[2]+10),
ylim=c(range_lat[1]-5, range_lat[2]+5))[c("x","y")])
#描画(大きさで太さが変わる)
ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE)) +
geom_path(aes(x, y, colour = NULL), map)
#軌道っぽくする(透明度を上げて見えるように)
ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE), shape = 1, alpha = 0.5) +
geom_path() +
geom_path(aes(x, y, colour = NULL), map)
#後細かい修正していたけど、省略
#画像で保存 ggsave
p<-ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE)) +
geom_path(aes(x, y, colour = NULL), map)
ggsave("test.png",p)
#ただし、RStudioのExportでもOK
■Rでできること
・Rコマンダー(Rcmdr)
install.packages("Rcmdr")
library(Rcmdr)
GUIでそうさできる
わからないものを勉強できる
・Rで形態素解析(RMeCab)
install.packages("RMeCab")
library(RMeCab)
rm<-RMeCabFreq("XXXXX.txt")
・RでSPARQL
install.packages("SPARQL")
library(SPARQL)
#DBPediaの内容から東京に関するものを採ってくる
#【手順1】URLを設定(DBPediaの)
url<-"http://dbpedia.org/sparql"
#【手順2】Select指定
query="SELECT *
WHERE {
<http://dbpedia.org/resource/Tokyo> ?p ?o
} LIMIT 400"
#【手順3】SPARQL実行!
res<-SPARQL(url=url,query=query)
#【手順4】表示
res
●このほかにも、RでHadoop,RでMongoDBとか・・
気象庁XMLのAPIに関しては
http://api.aitc.jp/
「R言語で始めよう、データサイエンス(ハンズオン勉強会)
〜機械学習・データビジュアライゼーション事始め〜」
に行ってきた!その内容のうち、(順番違うけど)ビジュアライゼーションをメモメモ
(基礎、機械学習、ビジュアライゼーション、Javascript連携と話は続く)
なお、この講義の基礎、機械学習、ビジュアライゼーション編は
http://www.slideshare.net/yasuyukisugai/r-28544592
の内容に沿って行われました。
(ソースプログラムはそのサイトより引用)
ビジュアライゼーション
ggplot2を使う
install.packages("ggplot2")
library(ggplot2)
# qplotクイックプロット
qplot(data=iris, x=Petal.Length, y=Petal.Width)
# 色分け:凡例つき
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species)
# 形で変える
qplot(data=iris, x=Petal.Length, y=Petal.Width, shape=Species)
# 大きさ
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species, size=Sepal.Length)
#層を重ねる(回帰曲線を重ねる)
qplot(data=iris, x=Petal.Length, y=Petal.Width)+stat_smooth()
qplot(data=iris, x=Petal.Length, y=Petal.Width, color=Species)+ stat_smooth()
#ヒストグラム
qplot(data=iris, x=Petal.Length, geom="histogram")
qplot(data=iris, x=Petal.Length, geom="histogram", fill=Species)
#密度グラフ
qplot(data=iris, x=Petal.Length, geom="density")
#半透明
qplot(data=iris, x=Petal.Length, geom="density", fill=Species, alpha=0.3)
●台風の軌道
データ
http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/besttrack.html
フォーマット
http://homepage3.nifty.com/typhoon21/general/bst-format.html
地図 maps
install.packages("maps")
library(maps)
#緯度経度
map(xlim=c(121, 155), ylim=c(20, 50))
#描画情報も取得できる
#データ取り込み
bst<-readLines('http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/Besttracks/bst2013.txt')
View(bst)
#ヘッダー(はじめが66666)を抜き出す
header <- read.table(textConnection(bst[grep("^66666", bst)]))
View(header)
#レコード部分(それ以外)を抜き出す
record<-read.table(textConnection(bst[-grep("^66666", bst)]),fill=TRUE)
#行の長さが違うので、入らないところカット
record<-record[!is.na(record[,7]),]
View(record)
#必要なところを採ってくる
header<-header[ , c(3,4,8)]
names(header) <- c("NROW", "TC_NO", "NAME")
View(header)
record<-record[ , c(1,3:7)]
names(record) <- c("DATE_TIME", "GRADE", "LAT", "LON", "HPA", "KT")
View(record)
#台風の識別番号をつける
record$TC_NO <- rep(header$TC_NO, header$NROW)
View(record)
#台風の識別番号をもとに結合
data <- merge(header, record, by = "TC_NO")
View(data)
#元データが10倍されているので、値変換transform
data <- transform(data, LAT = LAT / 10, LON = LON / 10)
View(data)
#ここまでで、データ処理終わり、あとはビジュアライゼーション
#範囲確認
range_lon<-range(data$LON)
range_lat<-range(data$LAT)
range_lon
range_lat
#座標パスXYだけを取得
map<-data.frame(map(plot=FALSE,
xlim=c(range_lon[1]-10, range_lon[2]+10),
ylim=c(range_lat[1]-5, range_lat[2]+5))[c("x","y")])
#描画(大きさで太さが変わる)
ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE)) +
geom_path(aes(x, y, colour = NULL), map)
#軌道っぽくする(透明度を上げて見えるように)
ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE), shape = 1, alpha = 0.5) +
geom_path() +
geom_path(aes(x, y, colour = NULL), map)
#後細かい修正していたけど、省略
#画像で保存 ggsave
p<-ggplot(data, aes(LON, LAT, colour = NAME)) +
geom_point(aes(size = GRADE)) +
geom_path(aes(x, y, colour = NULL), map)
ggsave("test.png",p)
#ただし、RStudioのExportでもOK
■Rでできること
・Rコマンダー(Rcmdr)
install.packages("Rcmdr")
library(Rcmdr)
GUIでそうさできる
わからないものを勉強できる
・Rで形態素解析(RMeCab)
install.packages("RMeCab")
library(RMeCab)
rm<-RMeCabFreq("XXXXX.txt")
・RでSPARQL
install.packages("SPARQL")
library(SPARQL)
#DBPediaの内容から東京に関するものを採ってくる
#【手順1】URLを設定(DBPediaの)
url<-"http://dbpedia.org/sparql"
#【手順2】Select指定
query="SELECT *
WHERE {
<http://dbpedia.org/resource/Tokyo> ?p ?o
} LIMIT 400"
#【手順3】SPARQL実行!
res<-SPARQL(url=url,query=query)
#【手順4】表示
res
●このほかにも、RでHadoop,RでMongoDBとか・・
気象庁XMLのAPIに関しては
http://api.aitc.jp/






















