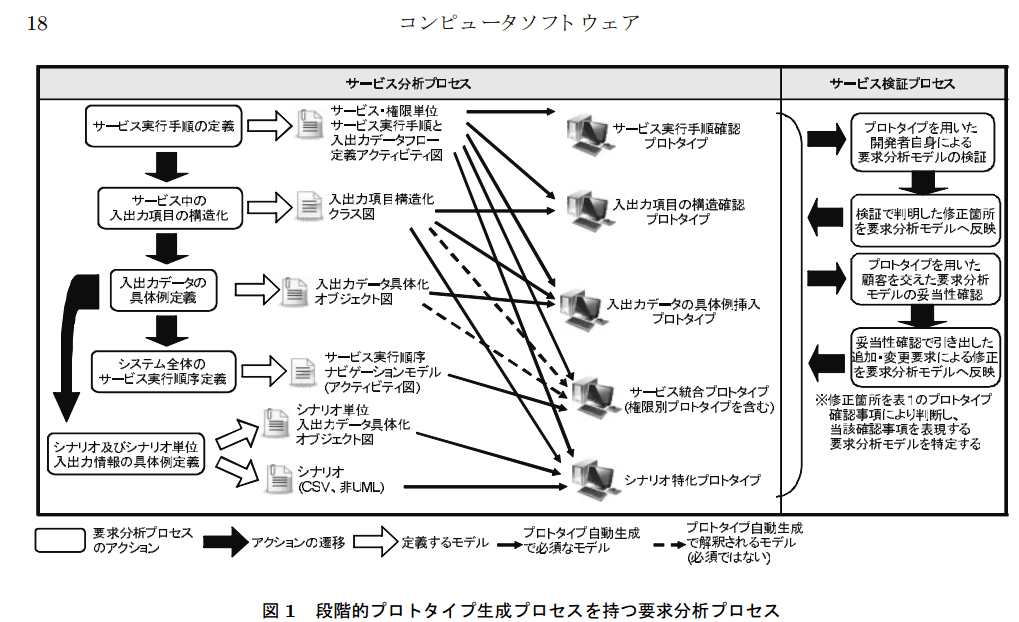
ちょっと日にちたっちゃったけど、前の
「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り?
http://blog.goo.ne.jp/xmldtp/e/2896922420cd01406a25f75606265c2a
に対して
きしだ @kis
いや、同じ次元じゃないと思う。アジャイルのほうが経験が盛り込まれてるので、読んで得るものがあるw 「「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り? - ウィリアムのいたずらの開発日記」 blog.goo.ne.jp/xmldtp/e/28969…
https://mobile.twitter.com/kis/status/316845583648321537
たしかに。そのとおり。
最近の大学・研究者の「ソフトウェア工学」は、実証的な経験から離れていき、現場と乖離している。
それは、大学・研究者にとっての「ソフトウェア工学」は、
ソフトウェアの工「学」
つまり、ソフトウェアを作る(工)という観点から見た「学問」
なのに対し、
現場の人の「ソフトウェア工学」のイメージは、
ソフトウェアで「工」学
つまり、ソフトウェアを使って、システムを作っていく(工)ために必要な学び
なのだ。この差が大きくなり、今の大学・研究所のソフトウェア工学が、
現場で使えないようになってきている。
ちょっと具体的に話そう。
■大学・研究者にとってのソフトウェア工学
ソフトウェア工学は大学・研究者においては、学問である。
つまり、「ソフトウェア工学」といわれたときに、それが示す範囲
(学問領域)があり、学として成立している。つまり、理論的に議論が
できるものと思われている。
たとえば、物理学を考えよう。この場合、理論的に議論が可能である。
その背景として、物理法則は、誰が、どこで、いつやっても同じ
結果になる。もし、そうならなければ、理論が成立しないので議論ができない。
りんごを落としたら、必ず地面に落ちるから、
万有引力の法則というのを考え議論できる
りんごをかじったら、歯茎から血が出るかどうかは、人によって違うので
デンターライオンの法則というのは物理学にはない
(古!通じないよ ^^;)
だから、大学のソフトウェア工学は、属人性の排除が重要で、技術として、
再利用可能であり、同じ結果が期待できるものとされている。
あるレベルの経験者しか持ち得ない暗黙知の技能に基づいた秘伝の技などは、
形式知にしない限り、研究対象からはずれる。
暗黙知の結晶である経験は、形式知にしないかぎり、学問対象から
外れてしまうのだ。
■結果として、アーキテクトでない人も大学でソフトウェア工学を教える
この結論として、大学・研究者にとってのソフトウェア工学とは
・ソフトウェア工学のドメインで
(プログラミングを除く、ソフトウェア開発過程で)
・適切なリサーチクエッションを提示し
・新たな方法で(形式知化できる手法で)
・数字により、優位性を明示できるもの
が対象となる。そして、論文を出さない限り博士になれず、博士にならない限り、
どんなにアーキテクトとして有能でも、現状では大学で教えることは難しい。
一方、ソフトウェアのアーキテクトの能力として疑問があり、
システム開発の経験が乏しい人でも、大学のソフトウェア工学の講義をうけもち、
アジャイルやウォーターフォールの批判を思う存分できることが
理論上(ということにしておきます・・)可能だ。
つまり、大学・大学院の間、システム設計をしないで、
論文を書き、博士をとる(この間、社会人経験なし)。
→これは可能。要求工学、ソフトウェアメトリクスの分野は、直接設計をしない
でも、論文は書ける。
そうすると、専門分野:ソフトウェア工学ということになる。
その後、大学の助教となり、ソフトウェア工学を教え、偉くなってしまうと・・・
ソフトウェア工学の権威として、まったく現場は知らないし、アーキテクトとしての
能力に疑問がある人でも、ソフトウェア工学の時間で、アジャイルやウォーターフォールの
批判はできる。
■現場の知識は、経験なので、暗黙知や属人性がはいりやすい
アジャイルでの実践にしろ、ウォーターフォールの実践にしろ、そこで得た知識は
経験にもとづく知識である。
このような知識は、暗黙知や属人性がはいりやすい。
アジャイルコーチを置くと、アジャイルが成功しやすいという経験を得たとしても、
すべてのアジャイルコーチでうまくいく・・・というわけでもないだろう(属人性)し、
それでは、どういうアジャイルコーチがいいのか・・・といわれたとき、その
特徴を列挙しずらいだろう(暗黙知)
ってことで、暗黙知や属人性がはいりやすく、このままでは、大学などの学問
にはなりにくい。
しかし、一般的には、現場では、このような知識のほうが、求められる。
たとえば
「プログラムを何本も写経すると、見えてくるものがある」
このことばは、現場の知識としては大事だし、何の違和感もない言葉だし、
私も経験したし、たぶん多くの人が経験することだし、新人に言う言葉だと思う。
だが、大学のソフトウェア工学の立場からみれば、何一つ説明していない無意味な言葉だ。
「見えてくるものってなに?」
「なぜ、写経すると・・?」
「どのプログラムでもそうなの?」
「なぜ、そんなことがいえるの?」
まず、こんな言葉が研究者から浴びせられるだろう。
現場の人はめんどくさいから無視し、研究者を避けるようになるだろう。
そして、暗黙知や経験に基づいた知識が現場に蓄積されるが、大学からはアプローチできず、差はどんどん広がっていく←イマココ
■現場と大学の知識の融合
では、この架け橋になる手法はないかというと、いくつかある。
1つは、パターン。
パターンなら、いくつかの事例から、パターン化を試みられる。
「アジャイル型開発におけるプラクティス活用事例調査」の報告書とリファレンスガイドを公開
http://sec.ipa.go.jp/reports/20130319.html
では、パターン・ランゲージに基づいて整理されているが、それは偶然というよりは、
必然なのかもしれない・・
また、海外であれば、「グラウンデッド・セオリー」がありえる。
グラウンデッド・セオリーは、データに基づき(グラウンデッド オン データ)現場の生の声のような
質的データから、仮説を構築していく手法であり、この手法であれば、経験者の言葉から、
経験上、有効な知見を見出し、仮説構築できる。
しかし、これは、海外の情報処理関係の学会では認められているし、
日本の教育・医療など、情報処理関係以外の学会では認められているが、
日本の情報処理学会で、グラウンデッド・セオリーを利用した、実務からの論文というのは、ほとんどない。
IEEE XploreでGrounded Theoryとひくと、8,555の検索結果が返ってくるが
日本の「情報学広場」で「グラウンデッド・セオリー」とひくと、12件しかない。
ただ、グラウンデッド・セオリーでまとめられないとき、エスノメソドロジーとして逃げる手がある。このエスノメソドロジーは、要求工学では認められているので、その線でいく?っていう手はあるかもしれない・・
ちょっとまとまりのない文になってしまったが、今のかんじは、こんなふうかな・・・
「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り?
http://blog.goo.ne.jp/xmldtp/e/2896922420cd01406a25f75606265c2a
に対して
きしだ @kis
いや、同じ次元じゃないと思う。アジャイルのほうが経験が盛り込まれてるので、読んで得るものがあるw 「「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り? - ウィリアムのいたずらの開発日記」 blog.goo.ne.jp/xmldtp/e/28969…
https://mobile.twitter.com/kis/status/316845583648321537
たしかに。そのとおり。
最近の大学・研究者の「ソフトウェア工学」は、実証的な経験から離れていき、現場と乖離している。
それは、大学・研究者にとっての「ソフトウェア工学」は、
ソフトウェアの工「学」
つまり、ソフトウェアを作る(工)という観点から見た「学問」
なのに対し、
現場の人の「ソフトウェア工学」のイメージは、
ソフトウェアで「工」学
つまり、ソフトウェアを使って、システムを作っていく(工)ために必要な学び
なのだ。この差が大きくなり、今の大学・研究所のソフトウェア工学が、
現場で使えないようになってきている。
ちょっと具体的に話そう。
■大学・研究者にとってのソフトウェア工学
ソフトウェア工学は大学・研究者においては、学問である。
つまり、「ソフトウェア工学」といわれたときに、それが示す範囲
(学問領域)があり、学として成立している。つまり、理論的に議論が
できるものと思われている。
たとえば、物理学を考えよう。この場合、理論的に議論が可能である。
その背景として、物理法則は、誰が、どこで、いつやっても同じ
結果になる。もし、そうならなければ、理論が成立しないので議論ができない。
りんごを落としたら、必ず地面に落ちるから、
万有引力の法則というのを考え議論できる
りんごをかじったら、歯茎から血が出るかどうかは、人によって違うので
デンターライオンの法則というのは物理学にはない
(古!通じないよ ^^;)
だから、大学のソフトウェア工学は、属人性の排除が重要で、技術として、
再利用可能であり、同じ結果が期待できるものとされている。
あるレベルの経験者しか持ち得ない暗黙知の技能に基づいた秘伝の技などは、
形式知にしない限り、研究対象からはずれる。
暗黙知の結晶である経験は、形式知にしないかぎり、学問対象から
外れてしまうのだ。
■結果として、アーキテクトでない人も大学でソフトウェア工学を教える
この結論として、大学・研究者にとってのソフトウェア工学とは
・ソフトウェア工学のドメインで
(プログラミングを除く、ソフトウェア開発過程で)
・適切なリサーチクエッションを提示し
・新たな方法で(形式知化できる手法で)
・数字により、優位性を明示できるもの
が対象となる。そして、論文を出さない限り博士になれず、博士にならない限り、
どんなにアーキテクトとして有能でも、現状では大学で教えることは難しい。
一方、ソフトウェアのアーキテクトの能力として疑問があり、
システム開発の経験が乏しい人でも、大学のソフトウェア工学の講義をうけもち、
アジャイルやウォーターフォールの批判を思う存分できることが
理論上(ということにしておきます・・)可能だ。
つまり、大学・大学院の間、システム設計をしないで、
論文を書き、博士をとる(この間、社会人経験なし)。
→これは可能。要求工学、ソフトウェアメトリクスの分野は、直接設計をしない
でも、論文は書ける。
そうすると、専門分野:ソフトウェア工学ということになる。
その後、大学の助教となり、ソフトウェア工学を教え、偉くなってしまうと・・・
ソフトウェア工学の権威として、まったく現場は知らないし、アーキテクトとしての
能力に疑問がある人でも、ソフトウェア工学の時間で、アジャイルやウォーターフォールの
批判はできる。
■現場の知識は、経験なので、暗黙知や属人性がはいりやすい
アジャイルでの実践にしろ、ウォーターフォールの実践にしろ、そこで得た知識は
経験にもとづく知識である。
このような知識は、暗黙知や属人性がはいりやすい。
アジャイルコーチを置くと、アジャイルが成功しやすいという経験を得たとしても、
すべてのアジャイルコーチでうまくいく・・・というわけでもないだろう(属人性)し、
それでは、どういうアジャイルコーチがいいのか・・・といわれたとき、その
特徴を列挙しずらいだろう(暗黙知)
ってことで、暗黙知や属人性がはいりやすく、このままでは、大学などの学問
にはなりにくい。
しかし、一般的には、現場では、このような知識のほうが、求められる。
たとえば
「プログラムを何本も写経すると、見えてくるものがある」
このことばは、現場の知識としては大事だし、何の違和感もない言葉だし、
私も経験したし、たぶん多くの人が経験することだし、新人に言う言葉だと思う。
だが、大学のソフトウェア工学の立場からみれば、何一つ説明していない無意味な言葉だ。
「見えてくるものってなに?」
「なぜ、写経すると・・?」
「どのプログラムでもそうなの?」
「なぜ、そんなことがいえるの?」
まず、こんな言葉が研究者から浴びせられるだろう。
現場の人はめんどくさいから無視し、研究者を避けるようになるだろう。
そして、暗黙知や経験に基づいた知識が現場に蓄積されるが、大学からはアプローチできず、差はどんどん広がっていく←イマココ
■現場と大学の知識の融合
では、この架け橋になる手法はないかというと、いくつかある。
1つは、パターン。
パターンなら、いくつかの事例から、パターン化を試みられる。
「アジャイル型開発におけるプラクティス活用事例調査」の報告書とリファレンスガイドを公開
http://sec.ipa.go.jp/reports/20130319.html
では、パターン・ランゲージに基づいて整理されているが、それは偶然というよりは、
必然なのかもしれない・・
また、海外であれば、「グラウンデッド・セオリー」がありえる。
グラウンデッド・セオリーは、データに基づき(グラウンデッド オン データ)現場の生の声のような
質的データから、仮説を構築していく手法であり、この手法であれば、経験者の言葉から、
経験上、有効な知見を見出し、仮説構築できる。
しかし、これは、海外の情報処理関係の学会では認められているし、
日本の教育・医療など、情報処理関係以外の学会では認められているが、
日本の情報処理学会で、グラウンデッド・セオリーを利用した、実務からの論文というのは、ほとんどない。
IEEE XploreでGrounded Theoryとひくと、8,555の検索結果が返ってくるが
日本の「情報学広場」で「グラウンデッド・セオリー」とひくと、12件しかない。
ただ、グラウンデッド・セオリーでまとめられないとき、エスノメソドロジーとして逃げる手がある。このエスノメソドロジーは、要求工学では認められているので、その線でいく?っていう手はあるかもしれない・・
ちょっとまとまりのない文になってしまったが、今のかんじは、こんなふうかな・・・


 ウィリアムのいたずら @xmldtp
ウィリアムのいたずら @xmldtp