








今、JMeter2.10と戯れていたら、
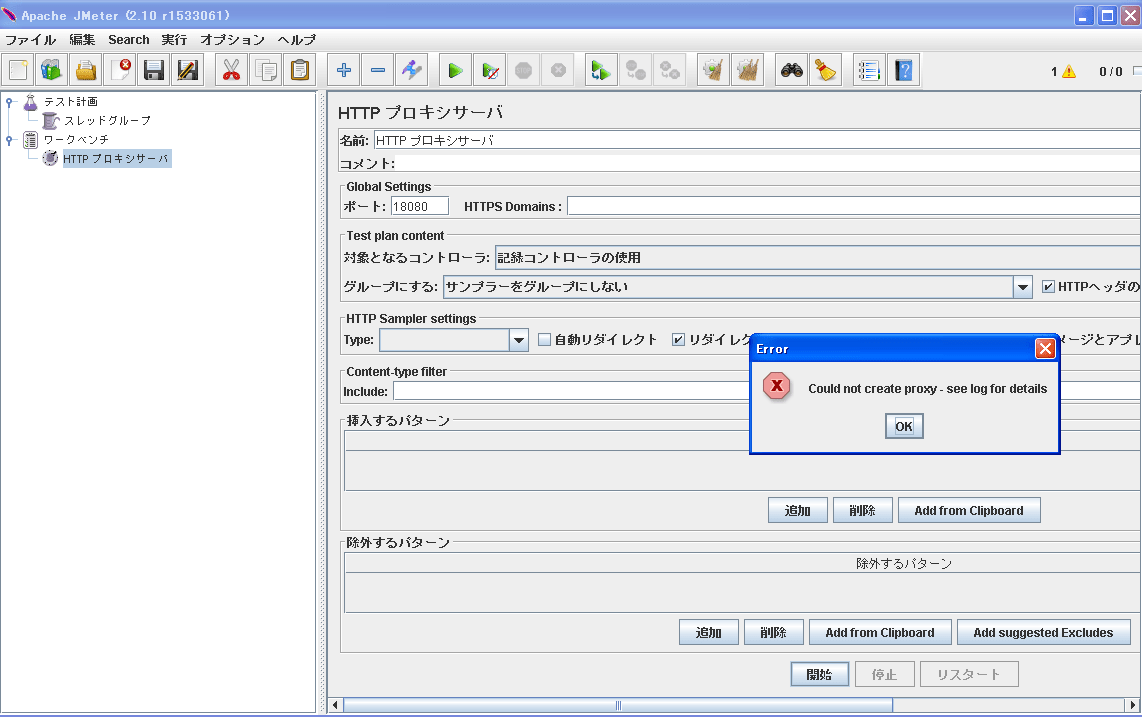
なエラーになった。
ログ見ろって書いてあるけど、めんどっちいので、
オプション→LogViewerにチェックを入れて、

下にログを出させるようにした。こんなかんじ。

そしたら出てきた、こんなエラーログ。
この下は、省略している。つまり、もっと出てくる。
どうも原因は、keytoolのあたりらしい。
ってことは、httpsあたりか・・・
・・・たしかにそこ、昔と変わってるよね!
■対策:ふるいバージョンに
ということで、2.10よりも前のバージョンに戻すことにした。
http://jmeter.apache.org/download_jmeter.cgi
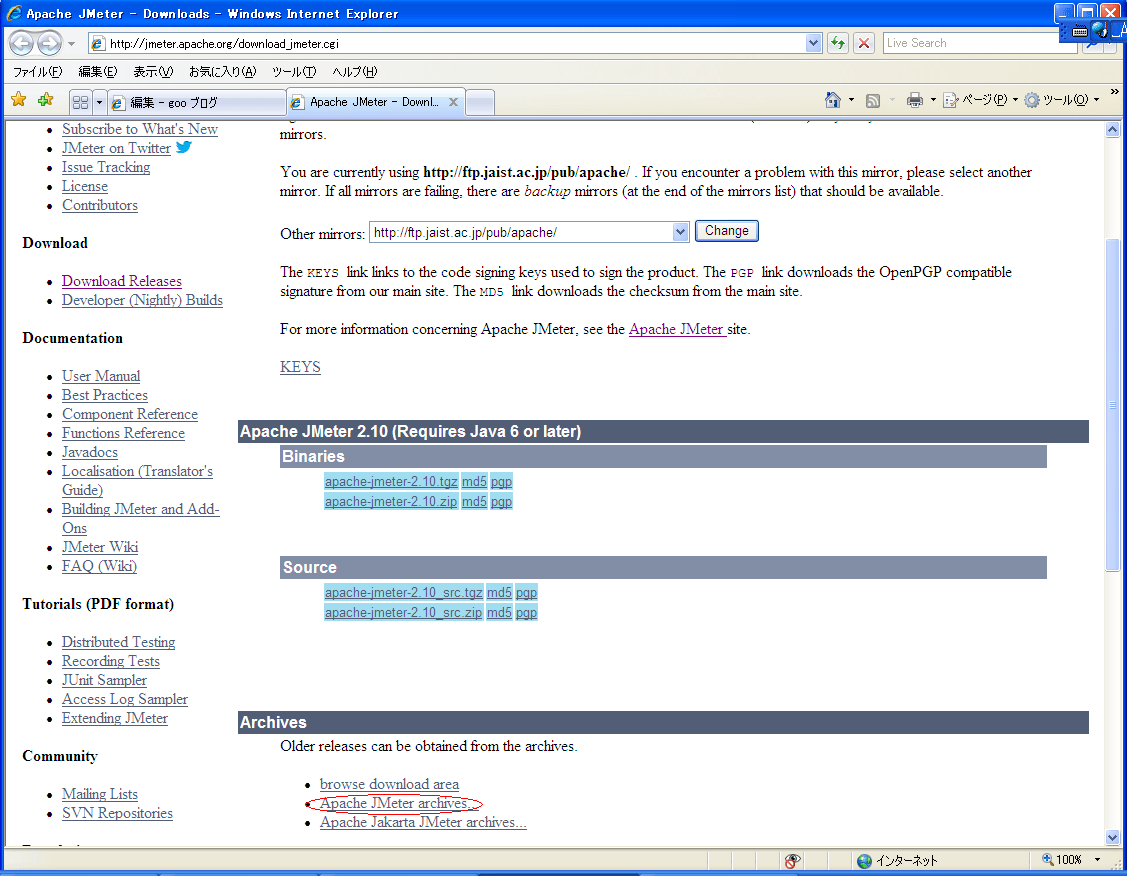
で、普段は、水色のあたりをクリックするけど、
もっとスクロールして、
「Apache JMeter archives... 」をクリック
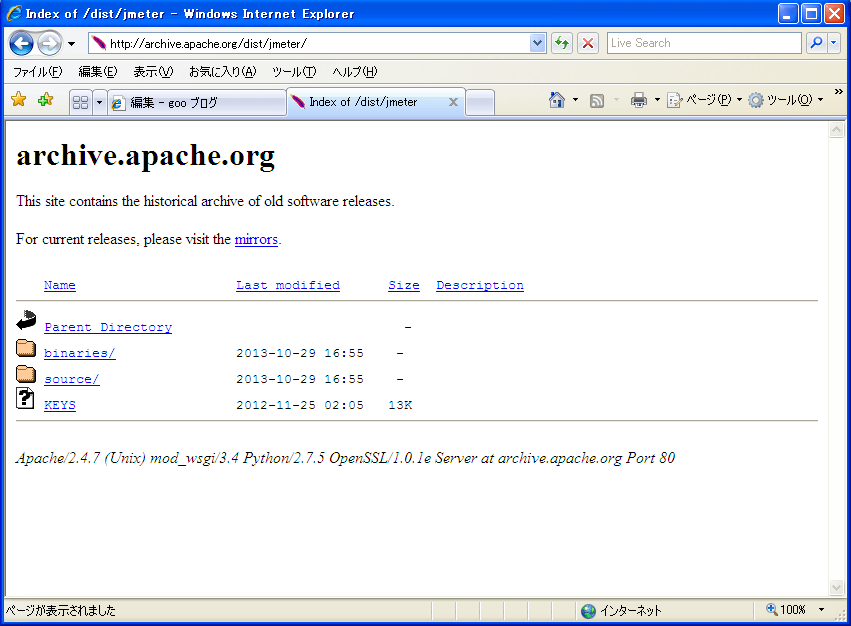
「binaries/」をクリック
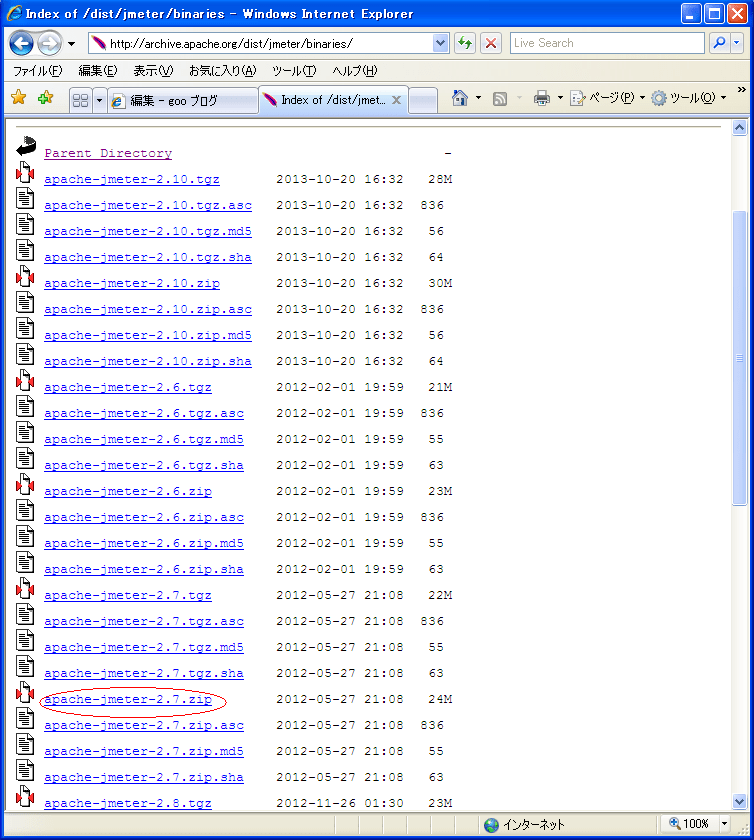
まあ「apache-jmeter-2.7.zip」でもクリックして、
ダウンロード、解凍してみてください。
■実際にやってみる:その前に準備
で、起動。するんだけど、その前に、ブラウザ側の設定しときます。
IEでやります。
オプション→インターネットオプションを選択すると

ダイアログが出るので、
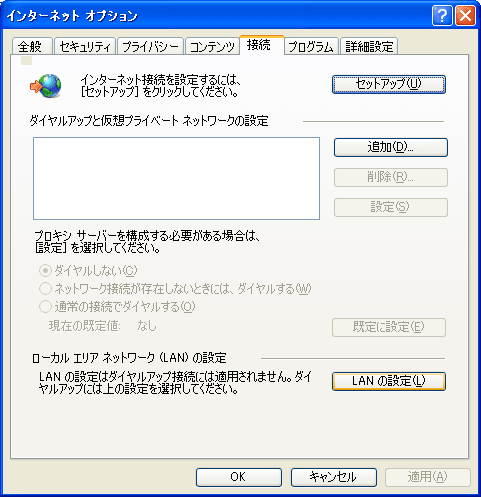
「接続」タブの「LANの設定」をクリック
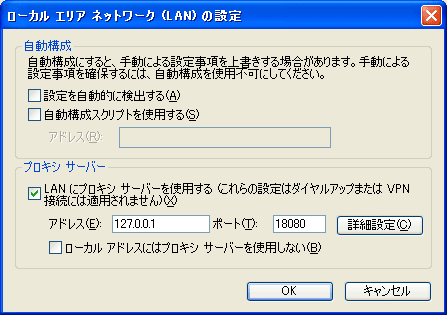
ローカルエリアネットワークの
プロキシサーバーの
上のチェックボックスチェック
その下のアドレスに、127.0.0.1とかいれて、
ポートは、あとで設定するJMeterのHTTPプロキシのポート番号。
なお、念をいれて、「詳細設定」をクリックし
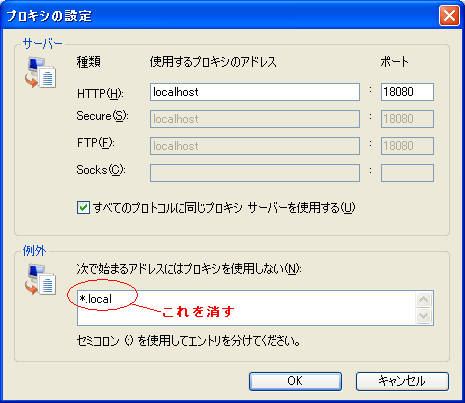
○で囲ったところを「消して」ローカルアドレスでも
プロキシ使用するようにする。
(けど、あとで書くけど、これでも、うまく行かないときがあるので、
プライベートのIPアドレスを直接打っている)
で、全部OKして、ブラウザを再立ち上げすると、
なにも表示できない(インターネットに繋がらない)
これは、まだJMeterでプロキシの設定をしていないから。
表示できないのが正しい。
もし、どっかのサイトにいけたら、おかしいので、
プロキシがちゃんと入っているか、チェック
■実際にやってみる:JMeter設定
では、JMeterを起動する
起動できたら、テスト計画を右クリックして

追加→Threads(Users)→スレッドグループ
でスレッドグループを作ったら、
ワークベンチを右クリック

追加→Non-Testエレメント→HTTPプロキシサーバ
を選択。
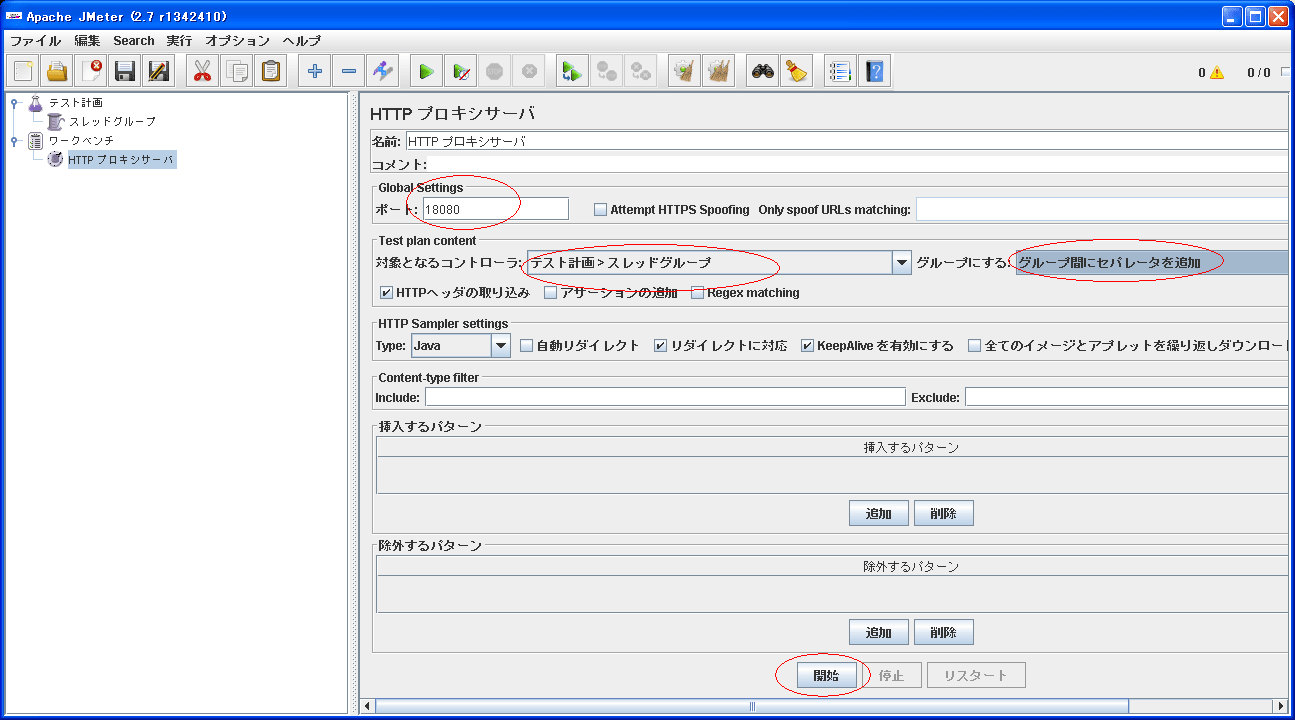
ポート番号は、IEに設定したポート番号、
コントローラーは、先ほど作ったスレッドグループを選択し、
グループごとにセパレータをいれたほうがわかりやすいので、そうした
そして、「開始」
これで、開始する
■実行!と、その結果
で、ブラウザで、自分の試験するところを指定するんだけど、
このとき、
127.0.0.1のようなループバック、
localhostのようなローカル指定だと、
うまくプロキシに入らないことがあるので、
プライベートアドレス(192.168.1.198とか)で打って見ると
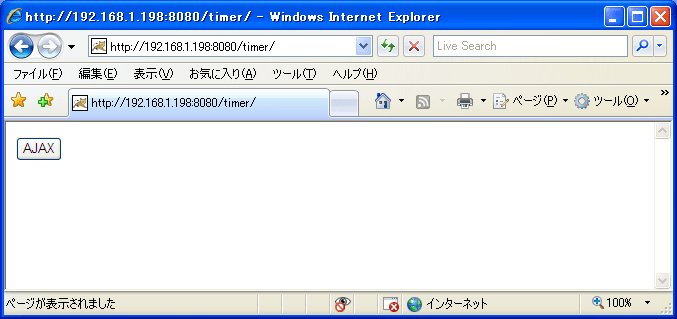
JMeterに呼び出した結果が入ってくる。

■おまけのなぞ・・・
で、なんか題名がはいっていない、4つのものがあるんだけど・・
見てみると・・・
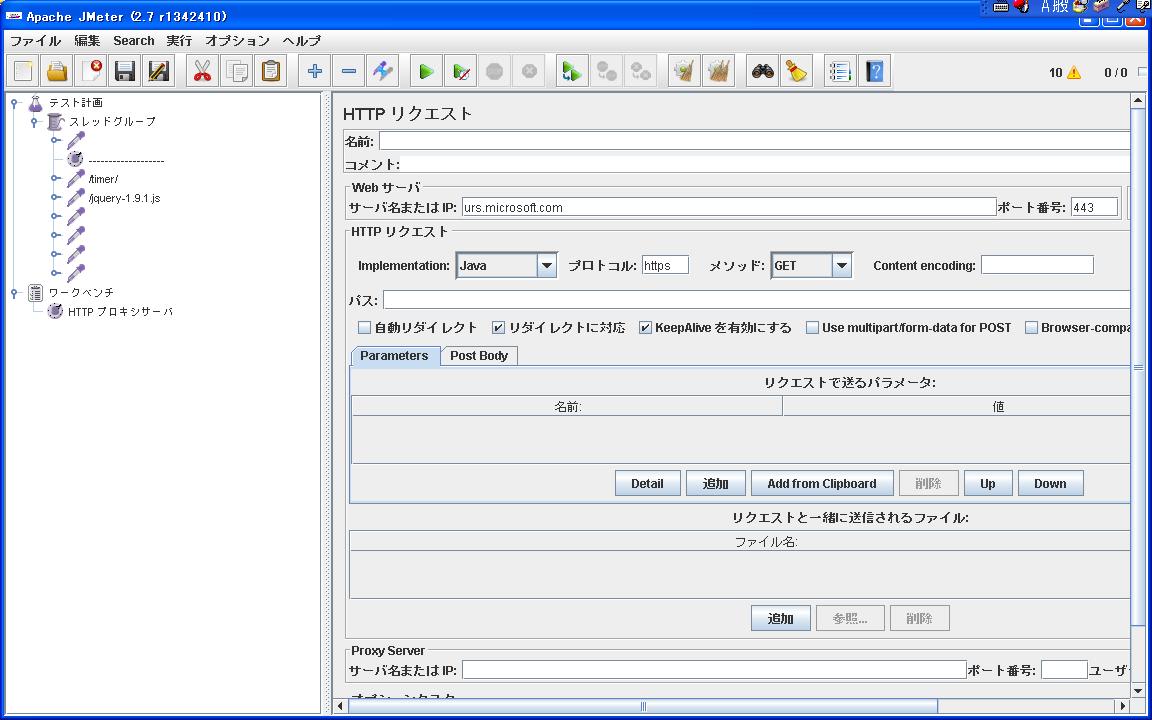
urs.microsoft.com??
この謎は、また今度かく。
なエラーになった。
ログ見ろって書いてあるけど、めんどっちいので、
オプション→LogViewerにチェックを入れて、
下にログを出させるようにした。こんなかんじ。
そしたら出てきた、こんなエラーログ。
2013/12/10 14:20:06 WARN - jmeter.protocol.http.proxy.ProxyControl: Could not open/read key store E:\いろいろ\apache-jmeter-2.10\bin\proxyserver.jks (指定されたファイルが見つかりません。) 2013/12/10 14:20:06 INFO - jmeter.protocol.http.proxy.ProxyControl: Creating Proxy CA in E:\いろいろ\apache-jmeter-2.10\bin\proxyserver.jks 2013/12/10 14:20:06 ERROR - jmeter.protocol.http.proxy.ProxyControl: Could not initialise key store java.io.IOException: Cannot run program "keytool" (in directory "E:\いろいろ\apache-jmeter-2.10\bin"): CreateProcess error=2, Žw’肳‚ꂽƒtƒ@ƒ at java.lang.ProcessBuilder.start(Unknown Source) at org.apache.jorphan.exec.SystemCommand.run(SystemCommand.java:142) at org.apache.jorphan.exec.SystemCommand.run(SystemCommand.java:125) at org.apache.jorphan.exec.KeyToolUtils.genkeypair(KeyToolUtils.java:123) |
この下は、省略している。つまり、もっと出てくる。
どうも原因は、keytoolのあたりらしい。
ってことは、httpsあたりか・・・
・・・たしかにそこ、昔と変わってるよね!
■対策:ふるいバージョンに
ということで、2.10よりも前のバージョンに戻すことにした。
http://jmeter.apache.org/download_jmeter.cgi
で、普段は、水色のあたりをクリックするけど、
もっとスクロールして、
「Apache JMeter archives... 」をクリック
「binaries/」をクリック
まあ「apache-jmeter-2.7.zip」でもクリックして、
ダウンロード、解凍してみてください。
■実際にやってみる:その前に準備
で、起動。するんだけど、その前に、ブラウザ側の設定しときます。
IEでやります。
オプション→インターネットオプションを選択すると
ダイアログが出るので、
「接続」タブの「LANの設定」をクリック
ローカルエリアネットワークの
プロキシサーバーの
上のチェックボックスチェック
その下のアドレスに、127.0.0.1とかいれて、
ポートは、あとで設定するJMeterのHTTPプロキシのポート番号。
なお、念をいれて、「詳細設定」をクリックし
○で囲ったところを「消して」ローカルアドレスでも
プロキシ使用するようにする。
(けど、あとで書くけど、これでも、うまく行かないときがあるので、
プライベートのIPアドレスを直接打っている)
で、全部OKして、ブラウザを再立ち上げすると、
なにも表示できない(インターネットに繋がらない)
これは、まだJMeterでプロキシの設定をしていないから。
表示できないのが正しい。
もし、どっかのサイトにいけたら、おかしいので、
プロキシがちゃんと入っているか、チェック
■実際にやってみる:JMeter設定
では、JMeterを起動する
起動できたら、テスト計画を右クリックして
追加→Threads(Users)→スレッドグループ
でスレッドグループを作ったら、
ワークベンチを右クリック
追加→Non-Testエレメント→HTTPプロキシサーバ
を選択。
ポート番号は、IEに設定したポート番号、
コントローラーは、先ほど作ったスレッドグループを選択し、
グループごとにセパレータをいれたほうがわかりやすいので、そうした
そして、「開始」
これで、開始する
■実行!と、その結果
で、ブラウザで、自分の試験するところを指定するんだけど、
このとき、
127.0.0.1のようなループバック、
localhostのようなローカル指定だと、
うまくプロキシに入らないことがあるので、
プライベートアドレス(192.168.1.198とか)で打って見ると
JMeterに呼び出した結果が入ってくる。
■おまけのなぞ・・・
で、なんか題名がはいっていない、4つのものがあるんだけど・・
見てみると・・・
urs.microsoft.com??
この謎は、また今度かく。







