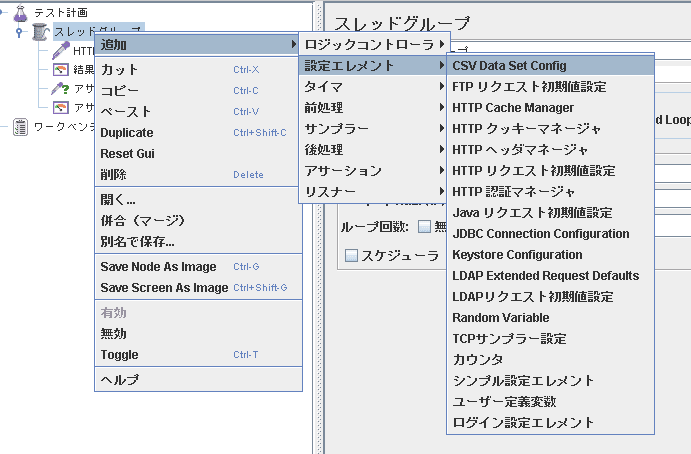
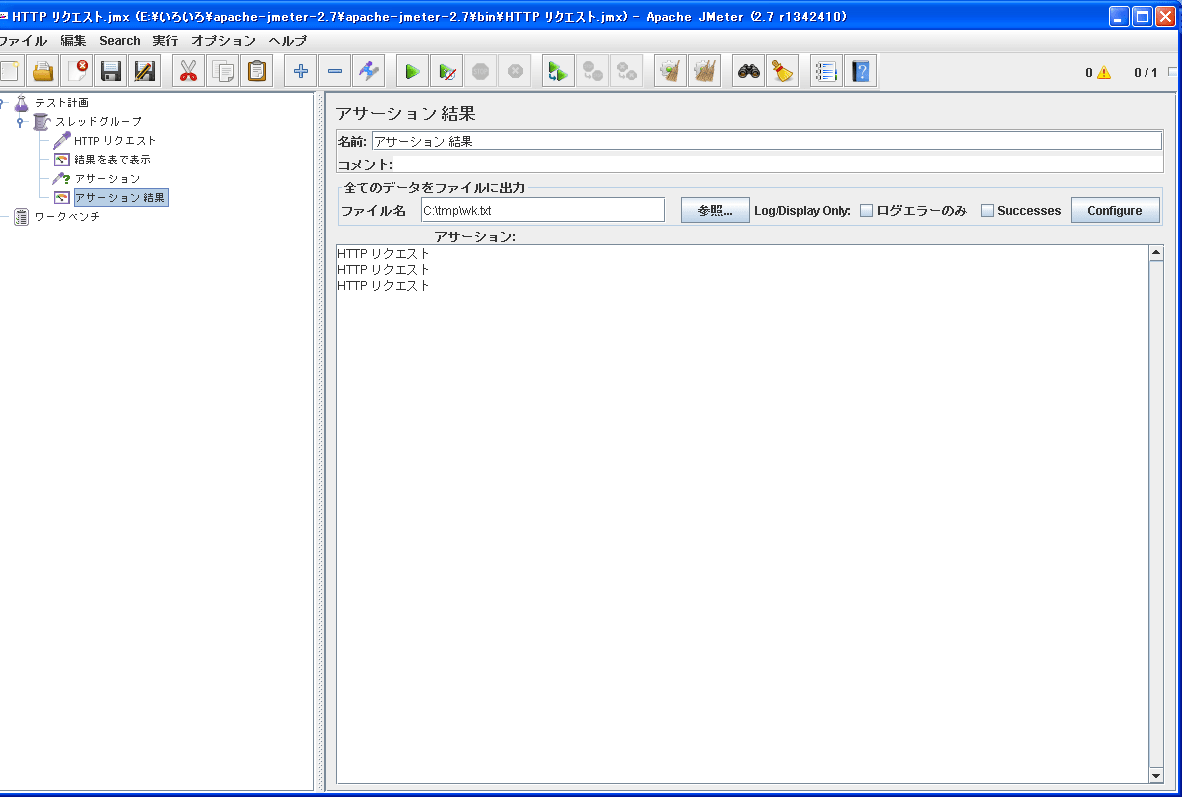
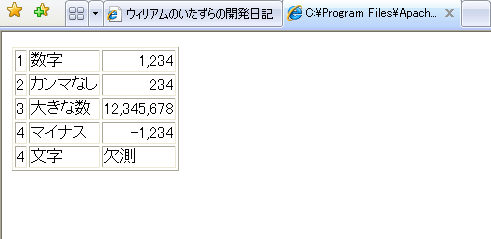
こんなかんじ(3桁目の数字と文字(欠測))。
これを、JavascriptとJQueryでやる方法の概要とサンプルコード
■概要
(1)テーブルのデータにidとクラスをつけます、
IDは、一意になるように
クラスをcomma3など、すべて共通にします
(2)JQueryで
$(function(){
$.each($(".comma3"), function() {
// (3)の処理
}
}
というふうに、(1)で指定したクラス全体に対して、(3)以降の処理を
行います。
(3)IDを取得して
myid = $(this).attr("id"); // id取得
mycssid = "#"+myid; // 後で使う
文字だったら
if ( isNaN(parseInt( $(this).text() )) )
{
// 左寄せ
$(mycssid).css("text-align","left");
}
数字だったら
else
{
// カンマをつけて
set_comma3(this);
// 右寄せ
$(mycssid).css("text-align","right");
}
とします。
(4)カンマ付け関数set_comma3()は、
[jQuery] 金額などの数値に3桁のカンマをセット
http://blog.aidream.jp/jquery/jquery-comma-three-digit-1870.html
を参考に作成
■ソースコード
これを、JavascriptとJQueryでやる方法の概要とサンプルコード
■概要
(1)テーブルのデータにidとクラスをつけます、
IDは、一意になるように
クラスをcomma3など、すべて共通にします
(2)JQueryで
$(function(){
$.each($(".comma3"), function() {
// (3)の処理
}
}
というふうに、(1)で指定したクラス全体に対して、(3)以降の処理を
行います。
(3)IDを取得して
myid = $(this).attr("id"); // id取得
mycssid = "#"+myid; // 後で使う
文字だったら
if ( isNaN(parseInt( $(this).text() )) )
{
// 左寄せ
$(mycssid).css("text-align","left");
}
数字だったら
else
{
// カンマをつけて
set_comma3(this);
// 右寄せ
$(mycssid).css("text-align","right");
}
とします。
(4)カンマ付け関数set_comma3()は、
[jQuery] 金額などの数値に3桁のカンマをセット
http://blog.aidream.jp/jquery/jquery-comma-three-digit-1870.html
を参考に作成
■ソースコード
<!doctype html>
<HTML>
<head>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.9.0/jquery.min.js"
type="text/javascript"></script>
<script>
$(function(){
$.each($(".comma3"), function() {
myid = $(this).attr("id"); // id取得
mycssid = "#"+myid;
if ( isNaN(parseInt( $(this).text() )) )
{ // 文字→左寄せ
$(mycssid).css("text-align","left");
}
else
{
// 数字→カンマつけて
set_comma3(this);
// 右寄せ
$(mycssid).css("text-align","right");
}
});
});
//--------------------------------
// カンマ付け
// 参考にしたサイト
// http://blog.aidream.jp/jquery/jquery-comma-three-digit-1870.html
//--------------------------------
function set_comma3(target)
{
var value = $(target).text();
if (isNaN(parseInt(value)) == false)
{
while (value != (value = value.replace(/^(-?\d+)(\d{3})/, ",")));
}
$(target).text(value);
}
</script>
<body>
<table border=1>
<tr><td>1</TD><td>数字</td><td id="data1td" class="comma3">1234</td></tr>
<tr><td>2</TD><td>カンマなし</td><td id="data2td" class="comma3">234</td></tr>
<tr><td>3</TD><td>大きな数</td><td id="data3td" class="comma3">12345678</td></tr>
<tr><td>4</TD><td>マイナス</td><td id="data4td" class="comma3">-1234</td></tr>
<tr><td>4</TD><td>文字</td><td id="data5td" class="comma3">欠測</td></tr>
</table>
</body>
</html>
|