










「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り?
http://blog.goo.ne.jp/xmldtp/e/2896922420cd01406a25f75606265c2a
に関する話題、第二段。
その中で、
Software Engineering: A Practitioner's Approach, 7th International edition
http://www.amazon.com/Software-Engineering-Practitioners-Approach-International/dp/0071267824
を挙げているけど・・・はい。この本、英語で、前書きいれると900ページ以上あります。
ってことで、こんな本を挙げていると、みんなから、無慈悲な稲妻を受けそうなので、
大事そうなところを、超訳&ななめ読みしてみたいと思います。
今日は、CHAPTER1、第一章、1ページ目(この前に前書きがあるけど、そこはローマ数字なので、
アラビア数字の1ページは、ここから)SOFTWARE AND SOFTWARE ENGINEERINGから、超訳&ななめ読み
第一章 ソフトウェアとソフトウェア工学
彼は、古めかしい格好をした、大手ソフトウェア会社の上級管理職。歳は40半ば、ちょっと白髪まじりだが整っていて、目は、話している間、聞き手(=私)に注がれている。
だが、彼の言ったことは、私にとって衝撃的だった。
「ソフトウエアは死んだ」
私は驚いて、目をぱちくりさせた。そして、微笑んだ
「冗談だろ!
世界はソフトウェアで回っていて、あんたの会社も、ソフトウェアのおかげで、そこそこ儲けている。
それが、死んだだって!生きてるし、成長しているだろ!!」
彼は、強調するように、頭を振った
「いや、死んだ・・・少なくとも、私がかつて知っていた、ソフトウェアは・・・」
私は、身を乗り出した。
「つづけて・・」
彼はテーブルをたたき、強調していった
「保守的な観点からみたソフトウェア、つまり、買って、所有し、保守する、こんなソフトウェアは、終わるだろう。
今日、Web2.0や拡張・強化されている情報処理は、まったく違った世代のソフトウェアだ。それは、インターネットを通じて届けられ、コンピューターデバイスに常駐している・・・んだけど、離れたサーバーにある」
私は、同意した。
「そう、人生はもっと単純になった。人々は、数千、数万のユーザーが、同じアプリなのに、違う5つのバージョンを持っているなんていう心配をする必要は、なくなった」
彼は言った
「まったくだ。たった1つの最新のバージョンがサーバーにあって、修正すると、機能的にアップデートされて、全ユーザーに届けられる。即座にね!」
私は、しかめっ面をした
「でも、もし間違えたらどうする。すべての人は、即座に同じように間違えるぞ(-_-;)」
彼は、含み笑いをした
「たしかに。だからこそ、ソフトウェア工学がよくなるように、より一層努力しなきゃいけないわけだ。
問題は、マーケットが加速しているため、私たちは速くやらなきゃいけないってことだ。
すべてのアプリの分野において」
私は、もたれかかり、彼のまえに手を広げた
「なんつーか、本中華(って、知っている人少ないよね~)
早くする、正しくする、安くする、この中から2つえらべ、
ちゅーこったな」
彼は、起き上がって言った
「速さと、正確さを選ぶ」
(そりゃそーさな。メーカーだから、お金は多くもらいたい。安いというのは選ばんよ)
わたしも立ち上がった
「つーことは、おまえさんも、ソフトウェア工学が必要なわけだ」
彼は、動きながら言った
「わかってるよ」
「問題は・・・だ、他の世代の技術者に、納得させることだ」
ここで、第1章の、はじまりの第1段落がおわり。
次に、第二段落もこのぐらいのレベルで訳して、
そのあと、本当に超訳(見出し+コメントくらい)にしていきたいと思う。
アジャイルは3章なので、順番にやると、もっと先になってしまう。
そこで、順番関係なしに、アジャイルだけ先にやる。
PHPの1.X系と、2.X系で何が違うのか
同じものを作って比較してみる。
前回モデルを使って、1.X系でのお話をしたので、
今回はモデルを使って、2.X系でのお話をする
■御題
CakePHPの1.X系と、2.X系で何が違うのか-その3
http://blog.goo.ne.jp/xmldtp/e/7cb8c389e19edc5e694cf720abf4580b
と同じ御題。
■追加・修正部分
ファイル構造は、
その1
http://blog.goo.ne.jp/xmldtp/e/493d369c8d635b3a269d4e02dcc7ae95
の2.XにModelが加わったかんじ。つまり、こんな感じ
app
|
|-Controller
| |
| *-MyTestController.php
|
|-Model
| |
| *-User.php
|
*-View
|
*-MyTest
|
|-hello.ctp
|
*-index.ctp
(赤字が追加修正箇所)
Modelが追加され、コントローラーが修正される
■追加部分に関して
追加するUser.phpの中身は、1.Xのときと一緒。
つまり、その3のuser.phpのファイルの中身と、まったく同じでよい。
■修正部分に関して
修正するMyTestController.phpは、はじめの引数を渡す部分だけは違うが(これは、その1のときに書いた)、あとは基本的にその3のuser.phpのファイルの中身と、同じでよい。以下のような感じ。
なかんじかな・・・
同じものを作って比較してみる。
前回モデルを使って、1.X系でのお話をしたので、
今回はモデルを使って、2.X系でのお話をする
■御題
CakePHPの1.X系と、2.X系で何が違うのか-その3
http://blog.goo.ne.jp/xmldtp/e/7cb8c389e19edc5e694cf720abf4580b
と同じ御題。
■追加・修正部分
ファイル構造は、
その1
http://blog.goo.ne.jp/xmldtp/e/493d369c8d635b3a269d4e02dcc7ae95
の2.XにModelが加わったかんじ。つまり、こんな感じ
app
|
|-Controller
| |
| *-MyTestController.php
|
|-Model
| |
| *-User.php
|
*-View
|
*-MyTest
|
|-hello.ctp
|
*-index.ctp
(赤字が追加修正箇所)
Modelが追加され、コントローラーが修正される
■追加部分に関して
追加するUser.phpの中身は、1.Xのときと一緒。
つまり、その3のuser.phpのファイルの中身と、まったく同じでよい。
■修正部分に関して
修正するMyTestController.phpは、はじめの引数を渡す部分だけは違うが(これは、その1のときに書いた)、あとは基本的にその3のuser.phpのファイルの中身と、同じでよい。以下のような感じ。
<?php
class MyTestController extends AppController {
public $uses = 'User';
public function index() {
}
public function hello() {
$yourname =$this->data['yourname'];
// DBアクセスして値取得
$condition = array("user_name" => $yourname);
$records = $this->User->find("first",array("conditions" => $condition));
if ( count($records['User']) > 0 )
{
$kaisu = $records['User']['kaisu'] + 1;
// DBアクセスして更新
$data['User'] = array('id' => $records['User']['id'], 'kaisu' => $kaisu);
$fields = array('kaisu');
$this->User->save($data, false, $fields);
}
else
{
$kaisu = 1;
// DBアクセスして追加
$data['User'] = array('user_name' => $yourname, 'kaisu' => 1);
$this->User->save($data);
}
// Viewに設定
$this->set('yourname',$yourname);
$this->set('kaisu',$kaisu);
}
}
|
なかんじかな・・・
なんか、
「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り?
http://blog.goo.ne.jp/xmldtp/e/2896922420cd01406a25f75606265c2a
の反響が大きいらしい・・・?
なので、ちょっと、これに関して、何点か、付け足しておく。
まず、第一点。
現在の日本のソフトウェア工学を論じるうえで、
「実は、astahを使って、要求から画面のソース作成までを一気通貫
(&自動生成)する方法は、論文が出ていて、無料で見られる」
っていう事実は知っておいたほうがいい。
そして、その手法の使い方を変えるだけで、ウォーターフォールから、
インクリメンタル、スパイラル、アジャイルが全部、導き出せる。
まず、その論文は、これ
UML要求分析モデルからの段階的なWeb UIプロトタイプ自動生成手法
コンピュータ ソフトウェアVol. 27 No. 2,日本ソフトウェア科学会(2010)
https://www.jstage.jst.go.jp/article/jssst/27/2/27_2_2_14/_pdf
ここで、示されている手法は以下のとおり
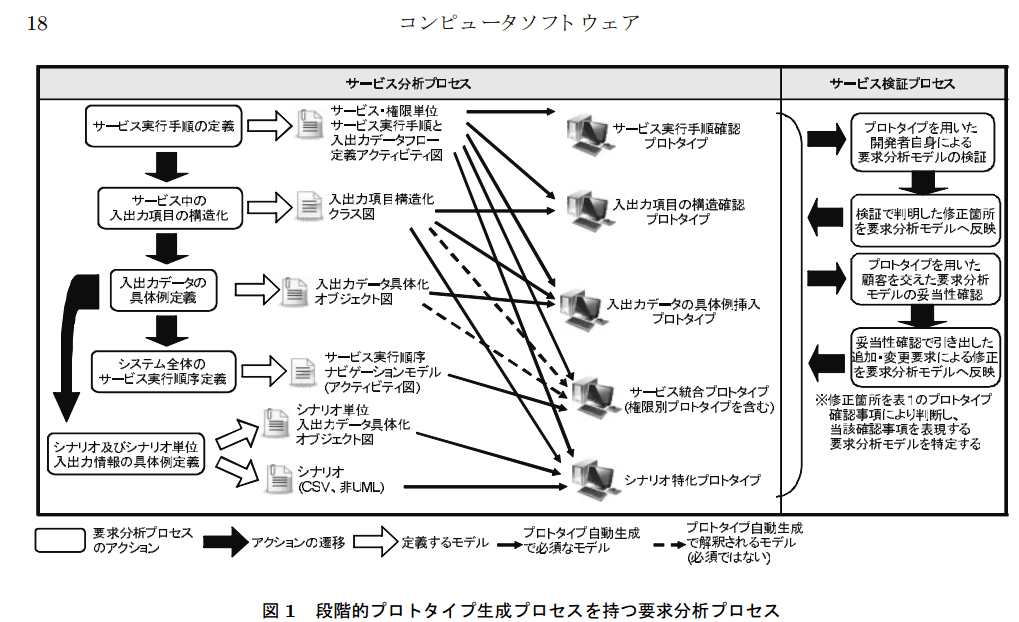
(上記の図は、上記論文より引用)
上流部分の一部は、この論文の対象外となっているようなので、そこを
付け加えて、全部書くと、こんな手順になる。
(ここは付け足した)
・なにをやりたいかをきめ、そのやりたいことに関する人を挙げる
人とやりたいことを結ぶと、ユースケース図になる。
ここで、やりたいことを、以下、「サービス」という
また、人は何でもしてよいわけではない。
何ができるかを決めたものを以下「権限」とよぶ
↓
(ここから、論文の内容)
・サービスの実行手順と、そのサービスの入出力をまとめ、
アクティビティ図に描く
→この論文で言っているアクティビティ図は、普通のアクティビティ図
と同じではないが、astahのアクティビティ図で書ける
↓
・その入出力項目の項目名と関連をしらべて、クラス図にまとめる
↓
・具体的にどんな値を入れるかを例を出して考え、オブジェクト図にまとめる
→ここで、検証する
→シナリオ単位の入出力にまとめる→テスト内容が確定する
↓
・サービスの実行手順をきめて(画面遷移→ナビゲーションが決まる)
アクティビティ図にまとめる
(論文には書いてないけど)
普通は画面遷移図だろうけど、
astahに画面遷移図はないからなあ~
↓
その画面をもとに、自動生成
この手法は、画面からデータ構造を決めている。
したがって、最近の画面→クエリ→DB作成の手法には向いているんだけど、
「DBは、正規化したもの」にする、従来の手法を用いる場合には、
クラス図にした入出力項目を元に、DBのテーブル(ないしER図)
を作ることになる。
この手法は、佐藤正美氏の本などに出ている。
ただ、この手の論文はでていないかな・・・
しかし、最近は正規化をしないので(CakePHPでbakeでつくるときなど)
これでもいいわけだ。
松浦先生のところで、小形先生(論文発表当時は、芝浦工大のたしかD?現在、信州大)がこの論文を出したので、ここから先、単にCakePHPとかで、全自動生成したとしても、卒論レベルならOKだけど、フルペーパーでは、ちょっとね・・・っていうレベルになった・・気がする。
ちょっと、脳内で妄想してみてね。
ある修士の院生が来て・・・
(院生)CakePHPで、要求から全自動でプログラミングを作るという「リサーチ・クエスチョン」で修士論文を書きたいと思います。
(先生)ほお、どう、アプローチするんだい。
(院生)まず、関連研究で、 「UML要求分析モデルからの段階的なWeb UIプロトタイプ自動生成手法」を挙げます
(先生)うん
(院生)そこで出てくるクラス図をastahでつくり、プラグインを作って、項目名を抽出、SQLを作成して、DBを自動生成します。
(先生)なるほど、DBは自動生成できるね。そこから・・・
(院生)はい、bakeをたたいて、DBからモデルを作ります。
(先生)・・・
(院生)そして、bakeをたたいて、モデルからコントローラーを作り、
最後に、bakeをたたいて、コントローラーからビューを作ります。
従来、手作業でやっていたことを、プログラムで自動化して行うので、
とてもはやく仕上がります!
(先生)それ、2年間で・・・
(院生)はい!(^^)v(満面の笑み)
(先生)・・・それって、3ヶ月ぐらいでできないか(^^;)・・・
bakeもいいけど、zfとか、symfonyとかもたたいてみて、
比較する気は、ないかね(^^;;;;・・・・・
卒論や研究会発表なら、ある方法論、まあcakePHPでもいいや、CORBAでもいいや、SOAP使っても、RESTでも
ソフトウェア工学は失敗している
http://d.hatena.ne.jp/nowokay/20130322#1363969460
に出てくる技術を一つ挙げて自動化っていうのも、アリだと思う。
ただ、修士論文以上、博士論文、フルペーパーになると、
それでは、スコープ小さすぎで、
・クラス図から項目名に基づき自動的に正規化し、DBの論理構造と
画面の物理構造を連結するコントローラー等を自動生成する手法
・cake,Zend,symfonyなど、いろいろな手法を切り替えて、自動生成できる
フレームワーク
ぐらいにならないと・・・
ただし、経験論文ならありだと思う。上記の手順で、実際に仕事を請けてやった場合の論文を、経験論文を受け付けている研究会で発表するのは、大アリだと思う。
だけど、そのとき、机上の空論をしてるんじゃ、もうだめぽで、そのとき、どういう問題があって、どう解決したかまでが、求められる。ただ、ここまでいくと、大学の先生や研究所ではできない
(そんなソフト開発のお仕事は請けないからね。大学は・・
・・・ただし産学連携IT授業として論文にするのはありかな)
次の話題。その手法の使い方を変えるだけで、ウォーターフォールから、
インクリメンタル、スパイラル、アジャイルが全部、導き出せるということだけど、
上記で自動生成は、要求→設計→コーディング(のはじめ:自動生成)まで行っている。
このまま、コーディングののこり(カスタマイズ部分)と、テストをやるとして、
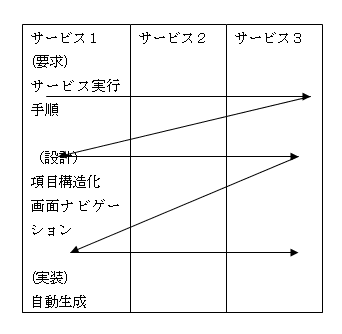
のように、まず、設計対象となる、全ての部分について、
・サービスの実行手順と、そのサービスの入出力をまとめ、
それが、全システム終わったら、設計段階ということで
・その入出力項目の項目名と関連をしらべて、クラス図にまとめる
さらにそれが全システム終わったらUI設計ということで、
・サービスの実行手順をきめて(画面遷移→ナビゲーションが決まる)
というように、全体が終わってから、次の工程にいくと、ウォーターフォールになる。
一方
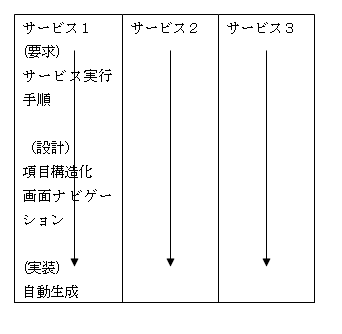
のように、全サービスをいくつかのサービスに分割し、その中で、
上記の要求、設計、UI、実装って入っていくと、
これは、インクリメンタルモデル。
スパイラルは、ベームが提唱した理論の場合、各フェーズでプロトタイプを
つくる。ってことは、一番初めに挙げている図1のカタチで、WFをやるに
過ぎない。
アジャイルは、基本的に、どの順番でやるかは、まかされている。
まあ、1つのサービスを一気に作っちゃったほうが、はやいかな?
W字開発は、オブジェクト図を作って、具体的データを考える(CSVとかつくる)
際に、テスト項目も考えると、設計時にテスト仕様書をつくることができる。
ってことで、この論文をベースに、いろんな開発プロセスにもっていけるわけよ。
で、この論文の先を、今、みんな考えているわけなんだけど、
まあ、それについては、このエントリ、いくらなんでも長くなりすぎたので、
このへんで切って、別の機会に。
「アジャイルがダメだと思う7つの理由」と「ソフトウェア工学は失敗している」は同じ次元の釣り?
http://blog.goo.ne.jp/xmldtp/e/2896922420cd01406a25f75606265c2a
の反響が大きいらしい・・・?
なので、ちょっと、これに関して、何点か、付け足しておく。
まず、第一点。
現在の日本のソフトウェア工学を論じるうえで、
「実は、astahを使って、要求から画面のソース作成までを一気通貫
(&自動生成)する方法は、論文が出ていて、無料で見られる」
っていう事実は知っておいたほうがいい。
そして、その手法の使い方を変えるだけで、ウォーターフォールから、
インクリメンタル、スパイラル、アジャイルが全部、導き出せる。
まず、その論文は、これ
UML要求分析モデルからの段階的なWeb UIプロトタイプ自動生成手法
コンピュータ ソフトウェアVol. 27 No. 2,日本ソフトウェア科学会(2010)
https://www.jstage.jst.go.jp/article/jssst/27/2/27_2_2_14/_pdf
ここで、示されている手法は以下のとおり
(上記の図は、上記論文より引用)
上流部分の一部は、この論文の対象外となっているようなので、そこを
付け加えて、全部書くと、こんな手順になる。
(ここは付け足した)
・なにをやりたいかをきめ、そのやりたいことに関する人を挙げる
人とやりたいことを結ぶと、ユースケース図になる。
ここで、やりたいことを、以下、「サービス」という
また、人は何でもしてよいわけではない。
何ができるかを決めたものを以下「権限」とよぶ
↓
(ここから、論文の内容)
・サービスの実行手順と、そのサービスの入出力をまとめ、
アクティビティ図に描く
→この論文で言っているアクティビティ図は、普通のアクティビティ図
と同じではないが、astahのアクティビティ図で書ける
↓
・その入出力項目の項目名と関連をしらべて、クラス図にまとめる
↓
・具体的にどんな値を入れるかを例を出して考え、オブジェクト図にまとめる
→ここで、検証する
→シナリオ単位の入出力にまとめる→テスト内容が確定する
↓
・サービスの実行手順をきめて(画面遷移→ナビゲーションが決まる)
アクティビティ図にまとめる
(論文には書いてないけど)
普通は画面遷移図だろうけど、
astahに画面遷移図はないからなあ~
↓
その画面をもとに、自動生成
この手法は、画面からデータ構造を決めている。
したがって、最近の画面→クエリ→DB作成の手法には向いているんだけど、
「DBは、正規化したもの」にする、従来の手法を用いる場合には、
クラス図にした入出力項目を元に、DBのテーブル(ないしER図)
を作ることになる。
この手法は、佐藤正美氏の本などに出ている。
ただ、この手の論文はでていないかな・・・
しかし、最近は正規化をしないので(CakePHPでbakeでつくるときなど)
これでもいいわけだ。
松浦先生のところで、小形先生(論文発表当時は、芝浦工大のたしかD?現在、信州大)がこの論文を出したので、ここから先、単にCakePHPとかで、全自動生成したとしても、卒論レベルならOKだけど、フルペーパーでは、ちょっとね・・・っていうレベルになった・・気がする。
ちょっと、脳内で妄想してみてね。
ある修士の院生が来て・・・
(院生)CakePHPで、要求から全自動でプログラミングを作るという「リサーチ・クエスチョン」で修士論文を書きたいと思います。
(先生)ほお、どう、アプローチするんだい。
(院生)まず、関連研究で、 「UML要求分析モデルからの段階的なWeb UIプロトタイプ自動生成手法」を挙げます
(先生)うん
(院生)そこで出てくるクラス図をastahでつくり、プラグインを作って、項目名を抽出、SQLを作成して、DBを自動生成します。
(先生)なるほど、DBは自動生成できるね。そこから・・・
(院生)はい、bakeをたたいて、DBからモデルを作ります。
(先生)・・・
(院生)そして、bakeをたたいて、モデルからコントローラーを作り、
最後に、bakeをたたいて、コントローラーからビューを作ります。
従来、手作業でやっていたことを、プログラムで自動化して行うので、
とてもはやく仕上がります!
(先生)それ、2年間で・・・
(院生)はい!(^^)v(満面の笑み)
(先生)・・・それって、3ヶ月ぐらいでできないか(^^;)・・・
bakeもいいけど、zfとか、symfonyとかもたたいてみて、
比較する気は、ないかね(^^;;;;・・・・・
卒論や研究会発表なら、ある方法論、まあcakePHPでもいいや、CORBAでもいいや、SOAP使っても、RESTでも
ソフトウェア工学は失敗している
http://d.hatena.ne.jp/nowokay/20130322#1363969460
に出てくる技術を一つ挙げて自動化っていうのも、アリだと思う。
ただ、修士論文以上、博士論文、フルペーパーになると、
それでは、スコープ小さすぎで、
・クラス図から項目名に基づき自動的に正規化し、DBの論理構造と
画面の物理構造を連結するコントローラー等を自動生成する手法
・cake,Zend,symfonyなど、いろいろな手法を切り替えて、自動生成できる
フレームワーク
ぐらいにならないと・・・
ただし、経験論文ならありだと思う。上記の手順で、実際に仕事を請けてやった場合の論文を、経験論文を受け付けている研究会で発表するのは、大アリだと思う。
だけど、そのとき、机上の空論をしてるんじゃ、もうだめぽで、そのとき、どういう問題があって、どう解決したかまでが、求められる。ただ、ここまでいくと、大学の先生や研究所ではできない
(そんなソフト開発のお仕事は請けないからね。大学は・・
・・・ただし産学連携IT授業として論文にするのはありかな)
次の話題。その手法の使い方を変えるだけで、ウォーターフォールから、
インクリメンタル、スパイラル、アジャイルが全部、導き出せるということだけど、
上記で自動生成は、要求→設計→コーディング(のはじめ:自動生成)まで行っている。
このまま、コーディングののこり(カスタマイズ部分)と、テストをやるとして、
のように、まず、設計対象となる、全ての部分について、
・サービスの実行手順と、そのサービスの入出力をまとめ、
それが、全システム終わったら、設計段階ということで
・その入出力項目の項目名と関連をしらべて、クラス図にまとめる
さらにそれが全システム終わったらUI設計ということで、
・サービスの実行手順をきめて(画面遷移→ナビゲーションが決まる)
というように、全体が終わってから、次の工程にいくと、ウォーターフォールになる。
一方
のように、全サービスをいくつかのサービスに分割し、その中で、
上記の要求、設計、UI、実装って入っていくと、
これは、インクリメンタルモデル。
スパイラルは、ベームが提唱した理論の場合、各フェーズでプロトタイプを
つくる。ってことは、一番初めに挙げている図1のカタチで、WFをやるに
過ぎない。
アジャイルは、基本的に、どの順番でやるかは、まかされている。
まあ、1つのサービスを一気に作っちゃったほうが、はやいかな?
W字開発は、オブジェクト図を作って、具体的データを考える(CSVとかつくる)
際に、テスト項目も考えると、設計時にテスト仕様書をつくることができる。
ってことで、この論文をベースに、いろんな開発プロセスにもっていけるわけよ。
で、この論文の先を、今、みんな考えているわけなんだけど、
まあ、それについては、このエントリ、いくらなんでも長くなりすぎたので、
このへんで切って、別の機会に。




