D. Huang, T. W. S. Chow
Effective Gene Selection Method With Small Sample Sets Using Gradient-Based and Point Injection Techniques
Computational Biology and Bioinformatics, IEEE/ACM Transactions on Volume 4, Issue 3, July-Sept. 2007 Page(s):467-475
[PDF][WebSite]
・ベイズ統計の評価関数(Bayesian discriminant-based criterion (BD))を再帰的に使って遺伝子を抽出する方法(SFS)を更に改良した方法2種を提案する。提案法は Gradient-based Strategy または Weighting-Sample Strategy と Point-Injection Strategy を使用する。
・データ
1.人工データ
2.実データ
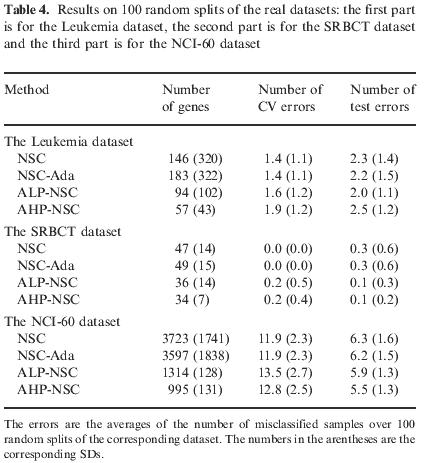
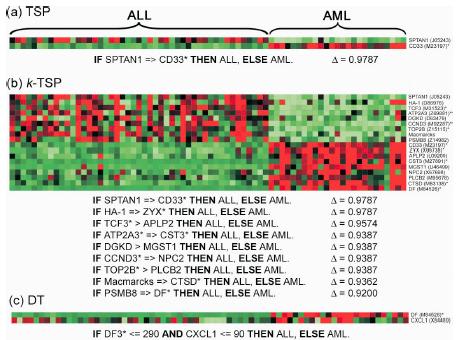
a.Colon Tumor
b.Prostate cancer
c.Leukemia subtype
・遺伝子抽出法
1.SFS (sequential forward search)
2.MSFS (modified SFS)(提案法)
3.WMSFS (modified SFS with the maximal-probability-weighting-injected-point strategy)(提案法)
・サンプルクラス分け法
1.Multiply percepton model (MLP)
2.Support vector machine with "Linear" kernel (SVM-L)
3.Support vector machine with "RBF" kernel (SVM-R)
4.3-nearest neighbor rule classifier (3-NN)
・方法「In this model, the employed search engine is the sequential forward search (SFS). The evaluation criterion is based on Bayesian discriminant [13].」
・方法「The first strategy is designed to enhance the effectiveness of searching. The second one addresses the problem of overfitting.」
・方法「A point injection approach is designed. The concept of the injection approach is to generate a number of points according to the distribution of given samples. Then, gene subsets can be assessed using the generated points and the original samples,.」
・前処理「In detail, for each given gene g, BD(g) is calculated based on (7), where w=1 for all samples. The genes with small values of BD are considered irrelevant and eliminated. In such as way, a huge gene set can be safely reduced」
Effective Gene Selection Method With Small Sample Sets Using Gradient-Based and Point Injection Techniques
Computational Biology and Bioinformatics, IEEE/ACM Transactions on Volume 4, Issue 3, July-Sept. 2007 Page(s):467-475
[PDF][WebSite]
・ベイズ統計の評価関数(Bayesian discriminant-based criterion (BD))を再帰的に使って遺伝子を抽出する方法(SFS)を更に改良した方法2種を提案する。提案法は Gradient-based Strategy または Weighting-Sample Strategy と Point-Injection Strategy を使用する。
・データ
1.人工データ
2.実データ
a.Colon Tumor
b.Prostate cancer
c.Leukemia subtype
・遺伝子抽出法
1.SFS (sequential forward search)
2.MSFS (modified SFS)(提案法)
3.WMSFS (modified SFS with the maximal-probability-weighting-injected-point strategy)(提案法)
・サンプルクラス分け法
1.Multiply percepton model (MLP)
2.Support vector machine with "Linear" kernel (SVM-L)
3.Support vector machine with "RBF" kernel (SVM-R)
4.3-nearest neighbor rule classifier (3-NN)
・方法「In this model, the employed search engine is the sequential forward search (SFS). The evaluation criterion is based on Bayesian discriminant [13].」
・方法「The first strategy is designed to enhance the effectiveness of searching. The second one addresses the problem of overfitting.」
・方法「A point injection approach is designed. The concept of the injection approach is to generate a number of points according to the distribution of given samples. Then, gene subsets can be assessed using the generated points and the original samples,.」
・前処理「In detail, for each given gene g, BD(g) is calculated based on (7), where w=1 for all samples. The genes with small values of BD are considered irrelevant and eliminated. In such as way, a huge gene set can be safely reduced」