








Caroline Truntzer, Catherine Mercier, Jacques Est?ve, Christian Gautier and Pascal Roy
Importance of data structure in comparing two dimension reduction methods for classification of microarray gene expression data
BMC Bioinformatics 2007, 8:90
[PDF]
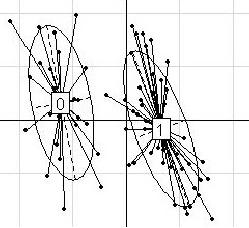
・複数の指標に基づいたサンプルの識別法の提案。横軸にBGA(Between-Group Analysis)、縦軸にPCA(Principal Componets Analysis)の第一成分または第二成分をとったグラフを作る。
・予備実験として以下の三法を人工データを用いて性能比較
1.PLS(Partial Least Squares) + DA(Discriminant Analysis)
2.PCA + DA
3.BGA
・データ:いずれもBioconductor("R")のpackageより入手
1.DLBCL : 58 patients (32 "cured" and 26 "fatal/refractory"), 6149 genes [Shipp]
2.Prostate : 102 patients (50 without and 52 with tumor), 12625 genes [Singh]
3.ALL : 125 patients (24 with and 101 without Multi Drug Pesistance -MDR-), 12625 genes [Chiaretti]
4.Leukemia : 72 patients (25 Acute Lymphoblastic Leukemia -ALL- and 47 Acute Myeloide Leukemia -AML-), 7129 genes [Golub]
・提案した識別法のプログラムは"R"で実行可能
・概要「This study evaluates the influence of gene expression variance structure on the performance of methods that describe the relationship between gene expression levels and a given phenotype through projection of data onto discriminant axes.」
・方法「To examine the structure of a dataset before analysis and preselect an a priori appropriate method for its analysis, we proposed a two-graph preliminary visualization tool: plotting patients on the Between-Group Analysis discriminant axis (x-axis) and on the first and the second within-group Principal Components Analysis component (y-axis), respectively.」
・問題点「However, in microarray experiments, there are more variables (genes) than samples (patients); if not taken into account, this dimension problem leads to trivial results with no statistical identifiability or biological singinficance.」
Importance of data structure in comparing two dimension reduction methods for classification of microarray gene expression data
BMC Bioinformatics 2007, 8:90
[PDF]
・複数の指標に基づいたサンプルの識別法の提案。横軸にBGA(Between-Group Analysis)、縦軸にPCA(Principal Componets Analysis)の第一成分または第二成分をとったグラフを作る。
・予備実験として以下の三法を人工データを用いて性能比較
1.PLS(Partial Least Squares) + DA(Discriminant Analysis)
2.PCA + DA
3.BGA
・データ:いずれもBioconductor("R")のpackageより入手
1.DLBCL : 58 patients (32 "cured" and 26 "fatal/refractory"), 6149 genes [Shipp]
2.Prostate : 102 patients (50 without and 52 with tumor), 12625 genes [Singh]
3.ALL : 125 patients (24 with and 101 without Multi Drug Pesistance -MDR-), 12625 genes [Chiaretti]
4.Leukemia : 72 patients (25 Acute Lymphoblastic Leukemia -ALL- and 47 Acute Myeloide Leukemia -AML-), 7129 genes [Golub]
・提案した識別法のプログラムは"R"で実行可能
・概要「This study evaluates the influence of gene expression variance structure on the performance of methods that describe the relationship between gene expression levels and a given phenotype through projection of data onto discriminant axes.」
・方法「To examine the structure of a dataset before analysis and preselect an a priori appropriate method for its analysis, we proposed a two-graph preliminary visualization tool: plotting patients on the Between-Group Analysis discriminant axis (x-axis) and on the first and the second within-group Principal Components Analysis component (y-axis), respectively.」
・問題点「However, in microarray experiments, there are more variables (genes) than samples (patients); if not taken into account, this dimension problem leads to trivial results with no statistical identifiability or biological singinficance.」




